
Save over 99.8% on audio transcription using Whisper Large V3 and consumer GPUs
A 99.8% cost-savings for automatic speech recognition sounds unreal. However, with the right choice of GPUs and models, this is very much possible and highlights the needless overspending on managed transcription services today. In this deep dive, we will benchmark the latest Whisper Large V3 model from Open AI for inference against the extensive English CommonVoice and Spoken Wikipedia Corpus English (Part1, Part2) datasets, delving into how we accomplished an exceptional 99.8% cost reduction compared to other public cloud providers.
Building upon the inference benchmark of Whisper Large V2 and with our continued effort to enhance the system architecture and implementation for batch jobs, we have achieved substantial reductions in both audio transcription costs and time while maintaining the same level of accuracy as the managed transcription services.
Behind The Scenes: Advanced System Architecture for Batch Jobs
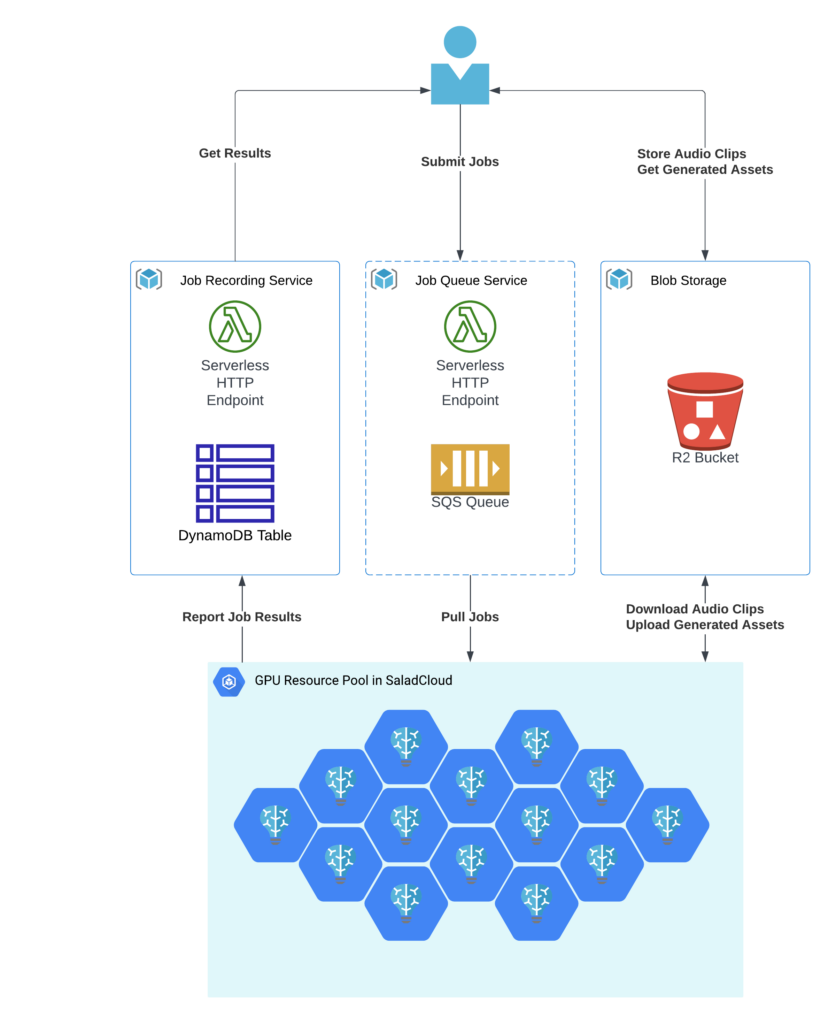
Our batch-processing framework comprises the following:
- GPU Resource Pool: Hundreds of Salad nodes equipped with dedicated GPUs for downloading and transcribing audio files, uploading generated assets, and reporting task results.
- Cloud Storage: Audio files and generated assets are stored in Cloudflare R2, which is AWS S3-compatible and incurs zero egress fees.
- Job Queue System: The Salad nodes retrieve jobs via AWS SQS, providing unique identifiers and accessible URLs for audio clips in Cloudflare R2. Direct data access without a job queue is also possible based on specific business logic. A HTTP handler using AWS Lambda can be provided for easy access.
- Job Recording System: Job results, including processing time, input audio URLs, output text URLs, etc., are stored in DynamoDB. An HTTP handler using AWS Lambda can be provided for easy access.
We aimed to keep the framework components fully managed and serverless to closely simulate the experience of using managed transcription services. A decoupled architecture provides the flexibility to choose the best and most cost-effective solution for each component from the industry.
Within each node in the GPU resource pool in SaladCloud, two processes are utilized following best practices: one dedicated to GPU inference and another focused on I/O and CPU-bound tasks, such as downloading/uploading, preprocessing, and post-processing.
1) Inference Process
The inference process operates on a single thread. It begins by loading the Whisper Large V3 model, warming up the GPU, and then listens on a TCP port by running a Python/FastAPI app in a Unicorn server. Upon receiving a request, it calls the transcription inference and returns the generated assets.
The chunking algorithm is configured for batch processing, where long audio files are segmented into 30-second clips, and these clips are simultaneously fed into the model. The batch inference significantly enhances performance by effectively leveraging the GPU cache and parallel processing capabilities.
2) Benchmark Worker Process
The benchmark worker process primarily handles various I/O tasks, as well as pre-and post-processing.
Multiple threads are concurrently performing various tasks: one thread pulls jobs and downloads audio clips; another thread calls the inference, while the remaining threads manage tasks such as uploading generated assets, reporting job results and cleaning the environment, etc. Several queues are created to facilitate information exchange among these threads.
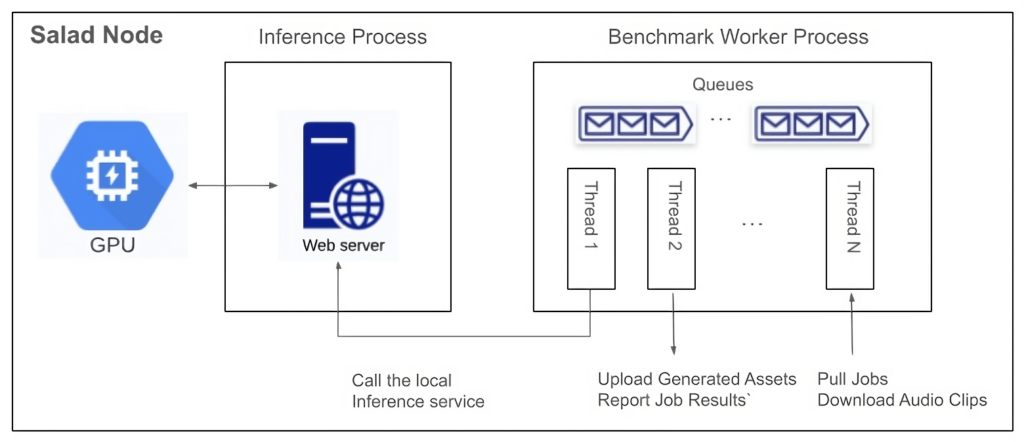
Running two processes to segregate GPU-bound tasks from I/O and CPU-bound tasks and fetching the next audio clips earlier while the current one is still being transcribed allows us to eliminate any waiting period. After one audio clip is completed, the next is immediately ready for transcription. This approach not only reduces the overall processing time for batch jobs but also leads to even more significant cost savings.
Deployment on SaladCloud
We created a container group with 100 replicas (2 vCPU and 12 GB RAM with 20 different GPU types) in SaladCloud, and ran it for approximately 10 hours. In this period, we successfully transcribed over 2 million audio files, totalling nearly 8000 hours in length. The test incurred around $100 in SaladCloud costs and less than $10 on both AWS and Cloudflare.
Results from the Whisper Large v3 benchmark
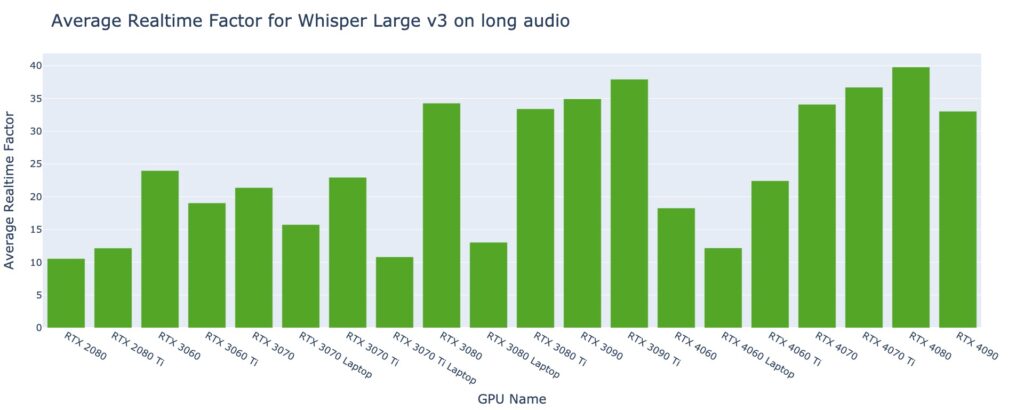
Among the 20 GPU types, based on the current datasets, the RTX 3060 stands out as the most cost-effective GPU type for long audio files exceeding 30 seconds. Priced at $0.10 per hour on SaladCloud, it can transcribe nearly 200 hours of audio per dollar.
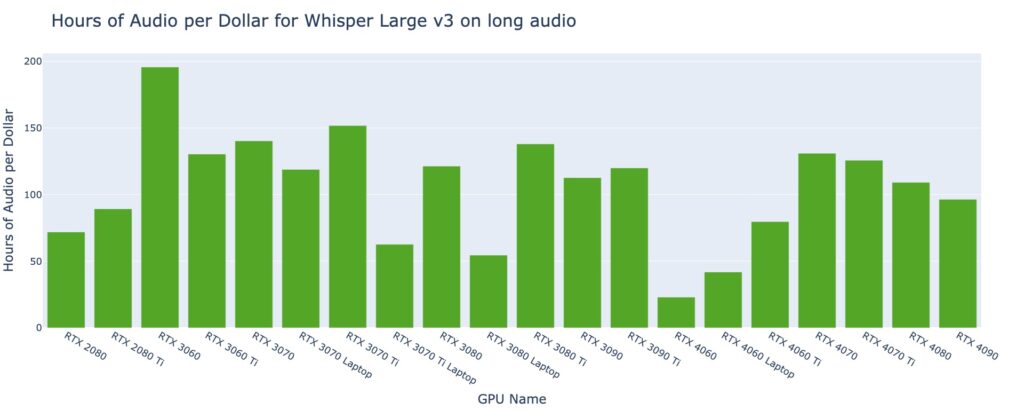
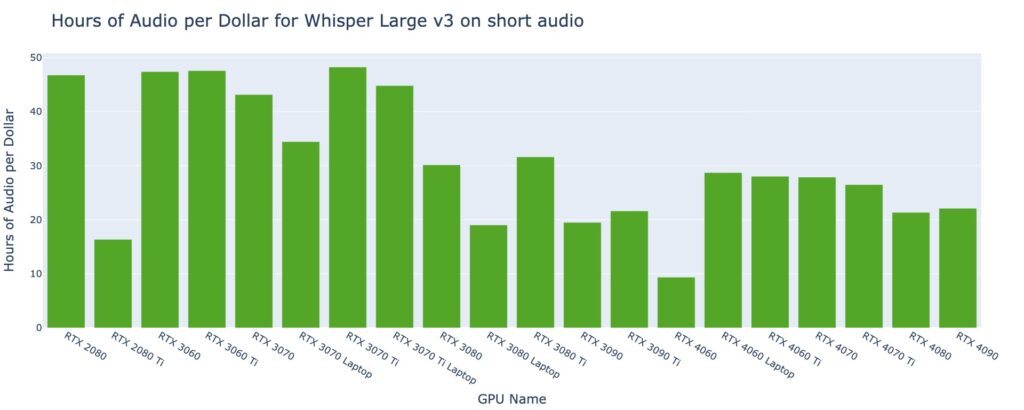
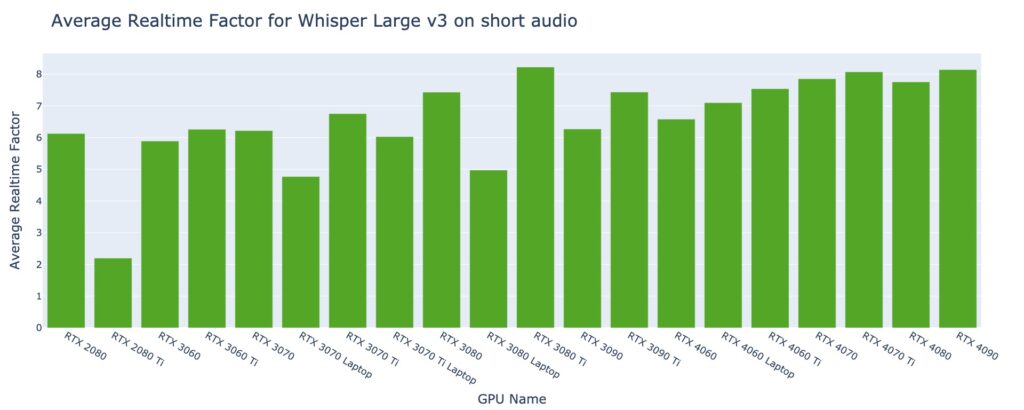
For short audio files lasting less than 30 seconds, several GPU types exhibit similar performance, transcribing approximately 47 hours of audio per dollar.
On the other hand, the RTX 4080 outperforms others as the best-performing GPU type for long audio files exceeding 30 seconds, boasting an average real-time factor of 40. This implies that the system can transcribe 40 seconds of audio per second.
For short audio files lasting less than 30 seconds, the best average real-time factor is approximately 8 by a couple of GPU types, indicating the ability to transcribe 8 seconds of audio in just 1 second.
Analysis of the benchmark results
Different from those obtained in local tests with several machines in a LAN, all these numbers are achieved in a global and distributed cloud environment that provides transcription at a large scale, including the entire process from receiving requests to transcribing and sending the responses.
There are various methods to optimize the results. Aiming for reduced costs, improved performance or even both, and different approaches may yield distinct outcomes.
The Whisper models come in five configurations of varying model sizes: tiny, base, small, medium, and large(v1/v2/v3). The large versions are multilingual and offer better accuracy, but they demand more powerful GPUs and run relatively slowly. On the other hand, the smaller versions support only English with slightly lower accuracy, but it requires less powerful GPUs and runs very fast.
Choosing more cost-effective GPU types in the resource pool will result in additional cost savings. If performance is the priority, selecting higher-performing GPU types is advisable, while still remaining significantly less expensive than managed transcription services.
Additionally, audio length plays a crucial role in both performance and cost, and it’s essential to optimize the resource configuration based on your specific use cases and business goals.
Discover our open-source code for a deeper dive:
Implementation of Inference and Benchmark Worker
Performance Comparison across Different Clouds
The results indicate that AI transcription companies are massively overpaying for the cloud today.
With the open-source automatic speech recognition model – Whisper Large V3, and the advanced batch-processing architecture leveraging hundreds of consumer GPUs on SaladCloud, we can deliver transcription services at a massive scale and at an exceptionally low cost while maintaining the same level of accuracy as managed transcription services.
With the most cost-effective GPU type for Whisper Large V3 inference on SaladCloud, $1 dollar can transcribe 11,736 minutes of audio (nearly 200 hours), showcasing a 500-fold cost reduction compared to other public cloud providers.
It’s worth noting that AWS Transcribe follows a billing structure that can significantly increase costs for shorter audio clips, which constitute the majority of the CommonVoice corpus. With a minimum per-request charge of 15 seconds, it introduces a challenge not encountered on per-second billing platforms. The cost-performance dynamics of AWS Transcribe may see improvement when dealing with longer content.
We tried to set up an apples-to-apples comparison by running the same batch-processing architecture on AWS ECS…but we couldn’t get any GPUs. The GPU shortage strikes again.
SaladCloud: The most affordable GPU cloud for massive audio transcription
For startups and developers eyeing cost-effective, powerful GPU solutions, SaladCloud is a game changer. Boasting the market’s lowest GPU prices, it offers a solution to sky-high cloud bills and limited GPU availability. As the speech-to-text market gets more crowded with multiple entrants, being able to deliver transcription at a massive scale at the lowest cost will determine who survives and thrives in this market.
The right choice of GPUs and cloud matters. For example, an AI company can go from spending $50,000 per month on a managed transcription service to spending $500 or less per month on SaladCloud, increasing profitability.
In an era where cost-efficiency and performance are paramount, leveraging the right tools and architecture can make all the difference. Our latest Whisper Large V3 Inference Benchmark is a testament to the savings and efficiency achievable with innovative approaches. We invite developers and startups to explore our open-source resources and discover the potential for themselves.
SaladCloud is the world’s largest distributed cloud computing network with 11,000+ daily GPUs and 450,000 GPUs contributing compute, all at the lowest cost in the market.


