
Save Over 99% On Audio Transcription Using Whisper-Large-v2 and Consumer GPUs
Harnessing the power of OpenAI’s Whisper Large V2, an automatic speech recognition model, we’ve dramatically reduced audio transcription costs and time. Here’s a deep dive into our benchmark against the substantial English CommonVoice dataset and how we achieved a 99.1% cost reduction.
A Costly Comparison
Traditionally, utilizing a managed service like AWS Transcribe would set you back about $10,500 for transcribing the entirety of the English CommonVoice dataset. Using a custom model? That’s an even steeper $13,134. In contrast, our approach using Whisper on SaladCloud incurred just $117, achieving the same result.
Behind The Scenes: Our Architecture
Our simple batch-processing framework comprises:
- Storage: Audio files stored in AWS S3.
- Queue System: Jobs queued via AWS SQS, with unique identifiers and accessible URLs for each audio clip.
- Transcription & Storage: Post transcription, results are stored in DynamoDB.
- Worker Coordination: We integrated HTTP handlers using AWS Lambda for easy access by workers to the queue and table.
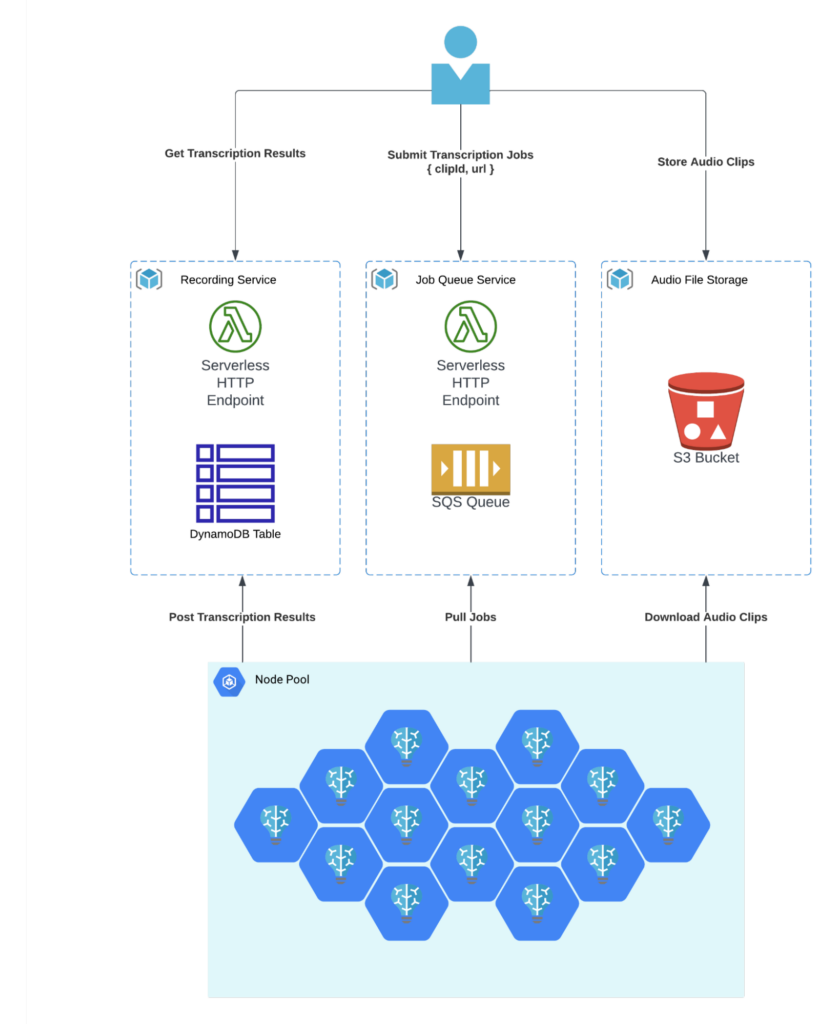
We wanted to keep the framework components fully managed and serverless to provide as close of an analog as possible to using managed transcription services. The framework itself incurred a cost of $28 during transcription, mainly due to S3 costs associated with uploading and downloading millions of files. This amount does not include any costs from the node pool.
Discover our open-source code for a deeper dive:
- Job Queue Service
- Recording Service
- Whisper Inference Server – Docker Image
- Whisper Benchmark Worker – Docker Image
Deployment on SaladCloud
With our inference container and services ready, we leveraged SaladCloud’s Public API. We used the API to deploy 2 identical container groups with 100 replicas each, all using the modest RTX 3060 with only 12GB of vRAM. We filled the job queue with urls to the 2.2 million audio clips included in the dataset, and hit start on our container groups. Our tasks were completed in a mere 15 hours, incurring $89 in costs from SaladCloud, and $28 in costs from our batch framework.
Performance Comparison of Whisper-Large-v2 Across Different Clouds
The result? An average transcription rate of one hour of audio every 16.47 seconds, translating to an impressive $0.00059 per audio minute. Notably, SaladCloud’s cost-performance ratio dramatically outshined major competitors, even when deploying custom models.
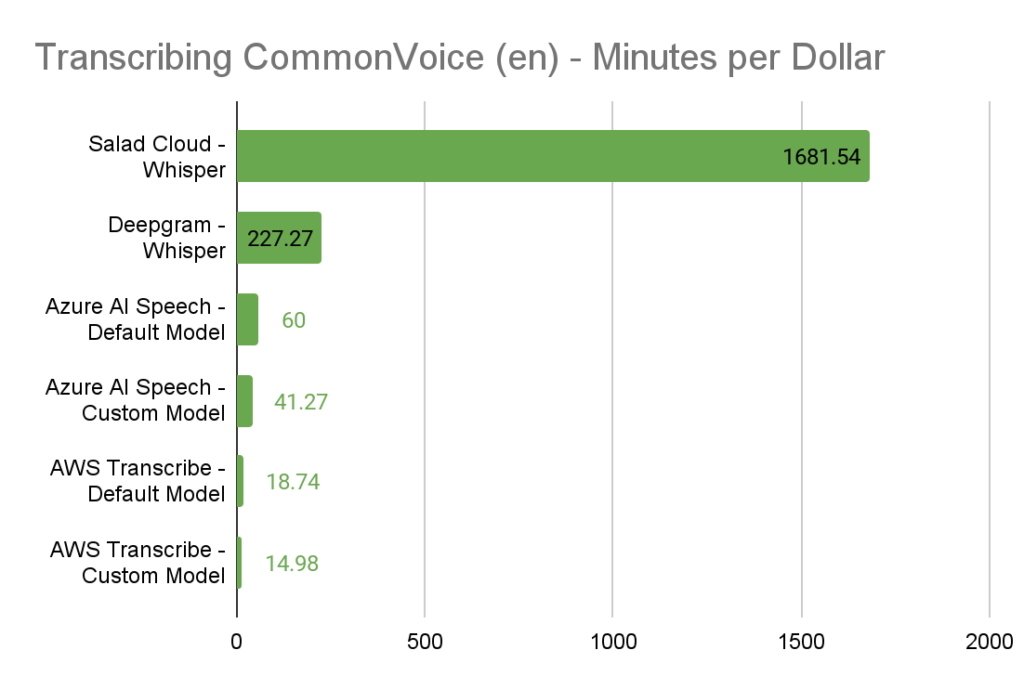
It’s worth noting that AWS Transcript’s billing structure can greatly inflate costs for shorter audio clips (which comprise most of the CommonVoice corpus), a setback not encountered on per-second billing platforms, and their cost performance would likely improve somewhat when transcribing longer content.
We tried to set up an apples-to-apples comparison by running our same batch inference architecture on AWS ECS…but we couldn’t get any GPUs. The GPU shortage strikes again.
Optimizing Further
While our benchmark results are already quite compelling, there are areas we’ve identified for potential performance enhancements:
- Eager Fetching: Our current setup results in GPUs momentarily sitting idle during the time it takes to fetch the next audio clip for transcription. By implementing an ‘eager fetching’ mechanism, the worker can preemptively download the subsequent audio clip even as the current one is still being processed. This parallelism ensures that by the time one clip is done, the next is immediately ready for transcription, thereby eliminating any waiting period.
- Batch Processing: Another approach could involve batch downloading, where multiple clips are fetched simultaneously, reducing the frequency of download requests and better utilizing the GPU’s capabilities. This approach would further reduce any downtime associated with data retrieval.
By integrating these process improvements, we anticipate that the overall transcription throughput could see an enhancement of 20-50% on this dataset. This would not only reduce processing time but also lead to even more significant cost savings, maximizing the efficiency of this approach.
SaladCloud: The Most Affordable GPU Cloud for AI Audio Transcription
For startups and developers eyeing cost-effective, powerful GPU solutions, SaladCloud is a game changer. Boasting the market’s most competitive GPU prices, it offers a solution to sky-high cloud bills and limited GPU availability.
In an era where cost-efficiency and performance are paramount, leveraging the right tools and architecture can make all the difference. Our Whisper Large Inference Benchmark is a testament to the savings and efficiency achievable with innovative approaches. We invite developers and startups to explore our open-source resources and discover the potential for themselves.


