The AI Infrastructure Paradox
The artificial intelligence revolution has reached a critical inflection point. While AI capabilities advance at breakneck speed, a fundamental bottleneck constrains innovation: infrastructure access. Today’s AI landscape presents a stark paradox: unprecedented demand for computational resources meets increasingly concentrated, expensive supply chains controlled by Big Tech monopolies.
The Challenge Landscape:
- GPU shortages create months-long waitlists for essential infrastructure
- Traditional cloud providers charge premium rates that can consume 70% of AI deployment budgets
- Manual model optimization requires months of specialized engineering work
- 400 million consumer GPUs worldwide lie idle most of the day
Innovation Barriers: Startups face impossible choices between proving product-market fit and securing massive infrastructure investments. Research institutions struggle to access computational resources for experimentation. Independent developers watch breakthrough ideas remain trapped in prototype stage due to deployment costs.
Meanwhile, the concentration of AI infrastructure in the hands of a few hyperscale providers creates systemic risks: from supply rationing to price manipulation that stifles innovation at its source.
Convergence of Vision: Why This Partnership Transforms Everything
Enter a strategic collaboration that challenges the fundamental assumptions of AI infrastructure: TheStage AI‘s breakthrough in automated neural network optimization, deployed at scale through Salad’s distributed GPU network. This partnership represents more than a technical integration: it’s a paradigm shift toward democratized, community-powered AI infrastructure.
Salad’s Democratization Mission: Built on the principle that cloud computing should be “by the people, for the people,” Salad has created the world’s largest distributed GPU network by tapping into latent consumer compute resources. Their platform transforms idle gaming PCs into enterprise-grade infrastructure, creating a sustainable alternative to traditional data centers while rewarding community members for their participation.
TheStage AI’s Optimization Revolution: Founded by former Huawei researchers and PhD mathematicians, TheStage AI has solved one of AI’s most persistent bottlenecks: the months-long manual process of neural network optimization. Their ANNA (Automated Neural Networks Analyzer) technology, based on award-winning CVPR research, reduces optimization time from months to hours while cutting deployment costs by up to 5x.
Strategic Alignment: Where Salad democratizes access to computational resources, TheStage AI democratizes the optimization expertise traditionally available only to large tech companies. Together, they eliminate both infrastructure and expertise barriers that have limited AI innovation to well-funded organizations.
Technical Innovation: The ANNA Breakthrough
Automated Neural Network Acceleration
TheStage AI’s ANNA represents a fundamental advancement in neural network optimization. Unlike traditional approaches that apply uniform algorithms across entire networks, ANNA employs sophisticated mathematical frameworks to analyze each layer individually, determining optimal acceleration strategies based on hardware constraints and quality requirements.
Core Innovation Principles:
- Layer-Specific Optimization: ANNA breaks down neural networks into constituent components, applying tailored algorithms to each part
- Quality-Preserving Compression: Mathematical guarantees ensure minimal quality degradation during optimization
- Hardware-Agnostic Deployment: Single checkpoints compile across diverse hardware platforms
- Automated Decision Making: Eliminates guesswork through rigorous algorithmic approaches
ANNA Optimization Process
TheStage AI leveraged their ANNA technology to generate optimized model variants strategically deployed across different GPU types based on memory constraints. ANNA’s intelligent approach generates multiple model sizes simultaneously, identifying the optimal quality configuration for each target size. This automated optimization process enables flexible deployment strategies that match hardware capabilities with performance requirements.
A typical ANNA optimization run demonstrates this capability:
# generates 10 sizes by defualt
results = ANNA.run(
model=model,
named_blocks=named_blocks,
bag_of_algorithms=bag,
dataloader=dataloader,
unpack_batch=unpack_batch,
convex_loss=convex_loss,
save_dir=output_dir
)After validating each model size, they obtain a quality degradation curve and can observe how benchmarks change as they move the slider. This straightforward approach lets them compress models to desired sizes while allowing them to select nearby points if the quality isn’t satisfactory.
Example of ANNA results visualized for Flux.1:
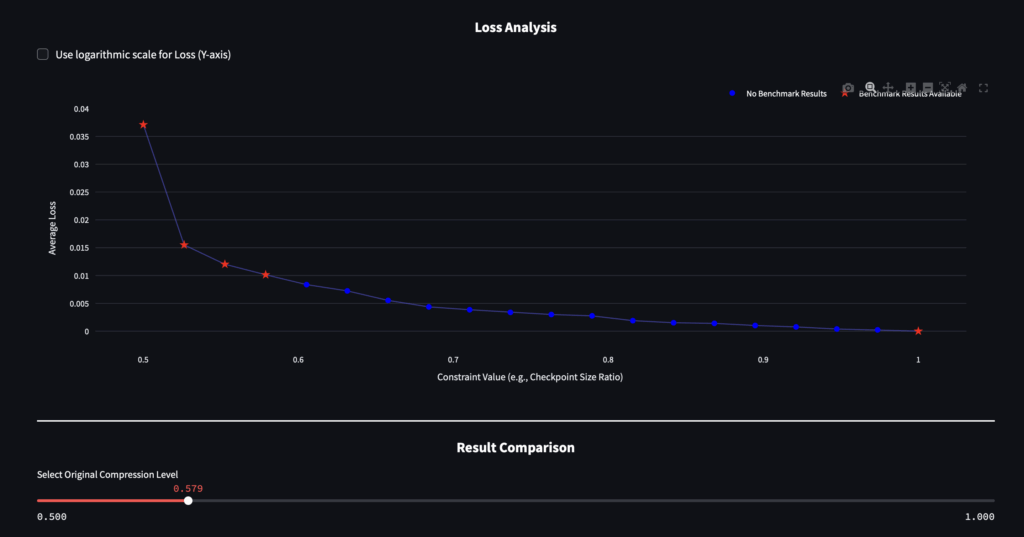
Quality Assurance Process:
Teams can easily compare generated images across different prompts with the original model and check validation metrics to select high-quality accelerated models. For the S model, they typically skip several layers and avoid using the most compressed model size, as this often leads to sudden quality degradation.
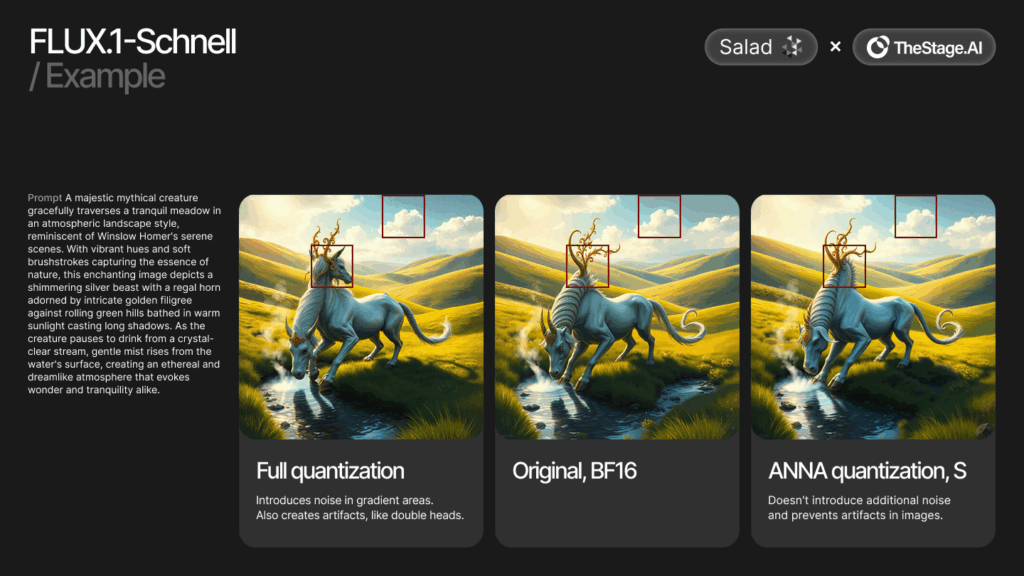
Example of different outputs for Flux.1[schnell], for S, M, L, XL and Original model.
Advanced Serving Infrastructure
TheStage AI has built a metaframework on Triton Inference Server that enables teams to leverage high-performance queuing systems and implement various batching strategies while maintaining the familiar PyTorch development experience. This approach addresses the common trade-off between serving performance and developer productivity by abstracting infrastructure complexity without requiring teams to abandon their existing model implementation patterns.
Key Technical Advantages:
- Developer-Friendly Integration: Maintains PyTorch workflows while optimizing for production
- Flexible Batching Strategies: Implements various queuing approaches for optimal resource utilization
- High-Performance Serving: Abstracts infrastructure complexity without sacrificing performance
- Organizational Accessibility: Makes enterprise-grade serving accessible without specialized expertise
To start diffusion model serving, the following steps can be implemented:
elastic-models serve \
# type of model and name
diffusion black-forest-labs/FLUX.1-schnell \
# model size from our library
--size S \
# max number of prompts to group
--batch 4 \
--enable-metadata-serverImplementation Excellence: Seamless Salad Deployment
Pre-Optimized Container Strategy
TheStage AI has developed pre-optimized Docker containers featuring Flux.1[Schnell] models, making deployment accessible through DockerHub for immediate use across teams and organizations. These production-ready containers eliminate the complexity of custom builds while ensuring optimal performance on target hardware.
Step-by-Step Deployment Process
To deploy optimized version of Flux Schnell on Salad’s distributed infrastructure:
1. Portal Access Navigate to portal.salad.com
2. Container Group Creation Create new container group
3. Recipe Selection Select “TheStage AI Elastic Models: Flux 1 Schnell” recipe
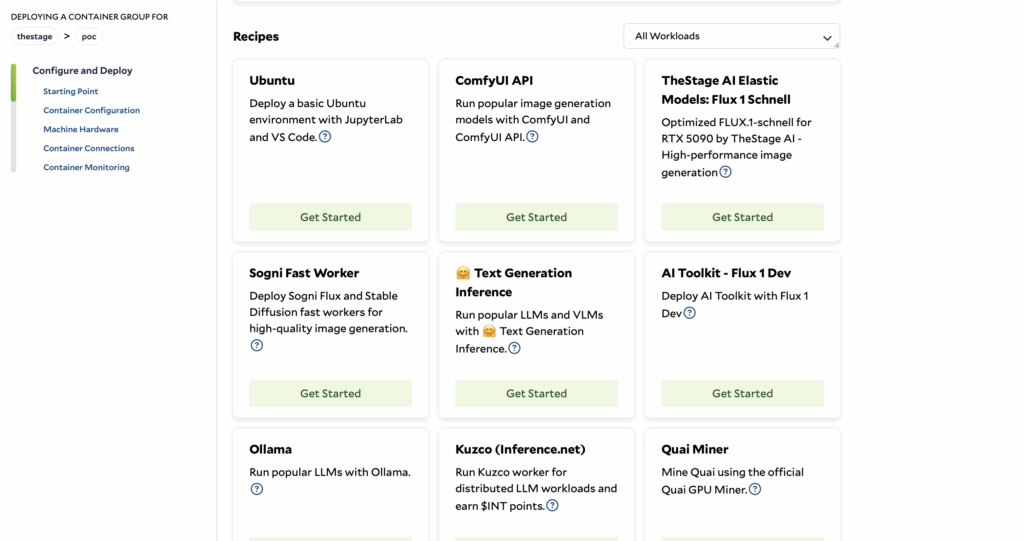
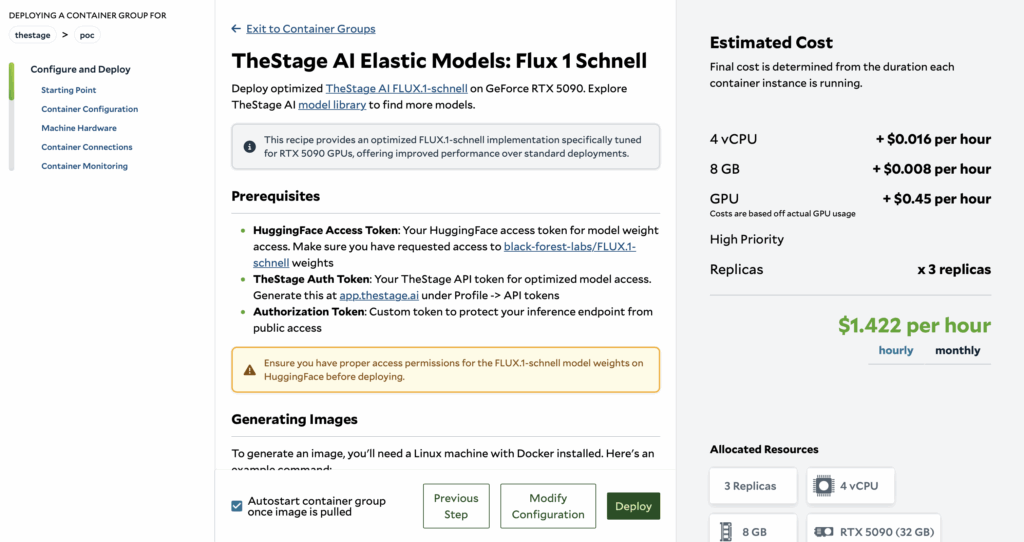
4. Authentication Setup
- Provide your HF token
- Provide your TheStage AI token (Generate at app.thestage.ai → Profile → API tokens)
- Provide authorization token to make endpoint private (can be random string)
5. Resource Configuration
- Setup desired number of replicas for RTX 5090 GPU (recommended: 8)
- Select desired priority for your GPUs (use “Batch” priority for lowest cost)
6. Deployment Verification
Once containers are deployed and in “running” state, you can send requests to another machine via the SaladCloud endpoint.
Client Integration Example
docker run \
-e THESTAGE_AUTH_TOKEN=$YOUR_THESTAGE_AUTH_TOKEN \
-e SALAD_ACCESS_DOMAIN_NAME=$SALAD_ACCESS_DOMAIN_NAME \
-v $(pwd)/output:/output \
public.ecr.aws/i3f7g5s7/thestage/elastic-models-client:0.0.14 \
bash -c 'elastic-models client diffusion \
--pos-prompt "photo of a cat" \
--inference-url $SALAD_ACCESS_DOMAIN_NAME \
--metadata-url $SALAD_ACCESS_DOMAIN_NAME/api/metadata \
--authorization "YOUR_AUTH_TOKEN"'Current Model Specifications
Model Limitations:
- Parameters ○ pos-prompt: positive prompt ○ authorization: your authorization token ○ weight: fixed, 1024 ○ height: fixed, 1024
- GPUs: ○ Precompiled only for Nvidia RTX 5090
Performance Validation: Rigorous Benchmarking
Comprehensive Testing Methodology
Benchmarking Configuration:
- Sample Size: 1024 images per user for statistical significance
- Concurrency Testing: 1, 2, 4, 8, 12, 16, 20, 24, 28, 32, 36 concurrent users
- Image Specifications: 1024×1024 resolution
- Hardware: RTX 5090 GPUs
- Infrastructure Scale: 8 replicas for robust performance assessment
Using TheStage AI client, teams can implement comprehensive Locust benchmarking with minimal configuration complexity. The systematic approach ensures reliable performance metrics across varying load conditions.
Breakthrough Performance Results
Peak Performance Metrics:
- Maximum RPS: 6.7 requests per second
- Optimal Response Time: 1.2 seconds per image
- Cost Efficiency: More than 10,000 images per dollar on Flux.1-Schnell
- Acceleration Factor: Up to 2.4x compared to traditional implementations
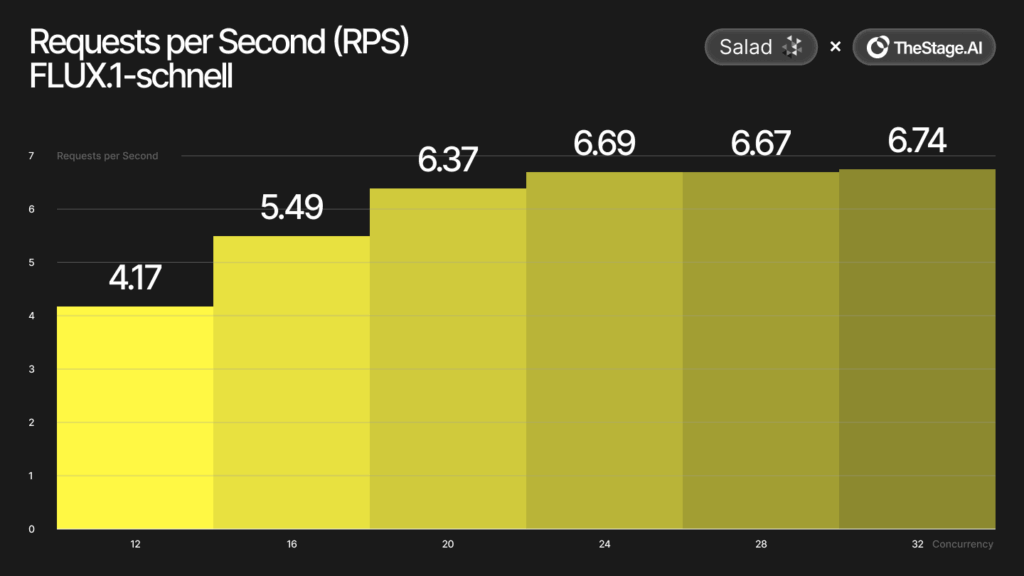
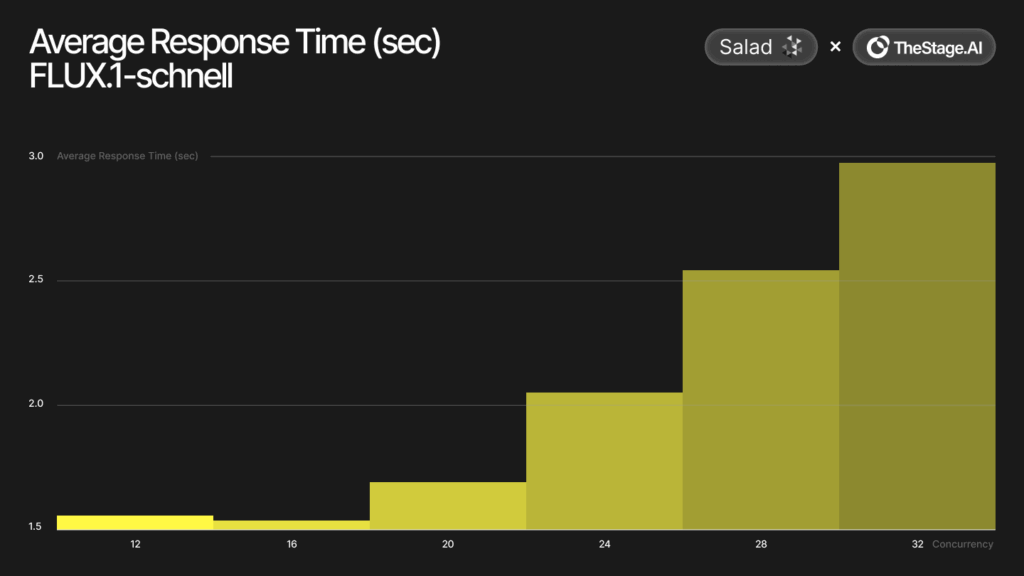
Technical Achievement Significance: These results represent more than incremental improvements: they demonstrate a fundamental shift in AI infrastructure economics. The combination of automated optimization and distributed deployment creates unprecedented cost-performance ratios that make enterprise-grade AI capabilities accessible to organizations regardless of infrastructure budget.
Conclusion: A New Era of AI Infrastructure
The partnership between TheStage AI and Salad represents more than a successful technical integration: it demonstrates a fundamental shift toward democratized, sustainable AI infrastructure. By achieving remarkable results like over 10,000 images per dollar and 1.2 second generation times, this collaboration proves that community-powered networks can deliver enterprise-grade capabilities while challenging traditional monopolistic structures.
Transformation Indicators:
- Technical Excellence: 2.4x acceleration with minimal quality degradation
- Economic Innovation: Up to 90% cost reduction compared to traditional cloud providers
- Community Empowerment: PC owners becoming infrastructure providers
- Global Accessibility: Breaking down barriers to AI innovation worldwide
Industry Implications: This success creates a template for future infrastructure development—one where community participation, automated optimization, and distributed resources combine to democratize access to cutting-edge capabilities. As AI workloads continue evolving toward more complex, real-time applications, partnerships like this establish the foundation for economically sustainable computational innovation.
The Path Forward: We stand at an inflection point where breakthrough performance becomes a catalyst for creativity rather than a constraint defined by capital resources. The traditional barriers between prototype and production deployment are dissolving, enabling teams to iterate rapidly with the same hardware configurations they’ll use at scale.
Getting Started: Teams seeking to transform computational efficiency challenges into competitive advantages can explore TheStage AI’s model optimization solutions at their website or contact [email protected]. Organizations ready to access cost-effective, distributed GPU infrastructure that scales with demand can connect with SaladCloud through the portal or sales team.
The future of AI infrastructure is distributed, optimized, and accessible to all.


