
Hugging Face Distil-Whisper Large V2 is a distilled version of the OpenAI Whisper model that is 6 times faster, 49% smaller, and performs within 1% WER (word error rates) on out-of-distribution evaluation sets. However, it is currently only available for English speech recognition.
Building upon the insights from the previous inference benchmark of Whisper Large V3, we have conducted tests with Distill-Whisper Large V2 by using the same batch-processing infrastructure, against the same English CommonVoice and Spoken Wikipedia Corpus English (Part1, Part2) datasets. Let’s explore the distinctions between these two automatic speech recognition models in terms of cost and performance, and see which one better fits your needs.
Batch-Processing Framework
We used the same batch processing framework to test the two models, consisting of:
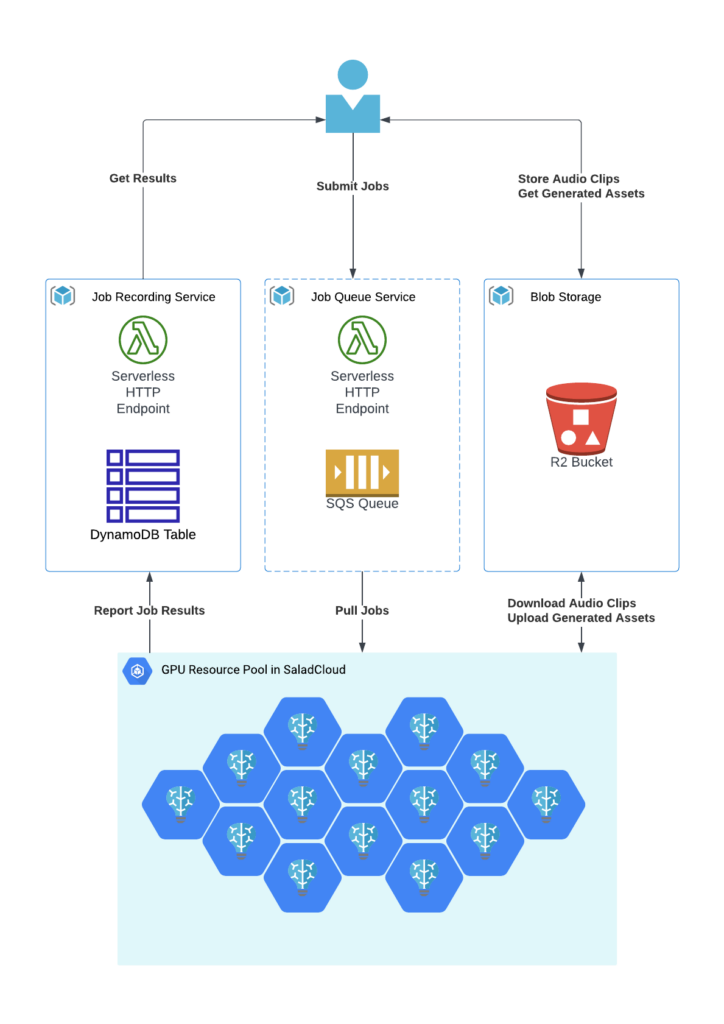
- GPU Resource Pool: Hundreds of Salad nodes equipped with dedicated GPUs. Within each node, two processes are utilized following best practices: one dedicated to GPU inference to transcribe audio files, and another focused on I/O- and CPU-bound tasks, such as pulling jobs and downloading audio files, uploading generated assets, and reporting task results.
- Cloud Storage: Audio files and generated assets are stored in Cloudflare R2, which is AWS S3-compatible and incurs zero egress fees.
- Job Queue System: The Salad nodes retrieve jobs via AWS SQS, providing unique identifiers and accessible URLs for audio clips in Cloudflare R2. Direct data access without a job queue is also possible based on specific business logic.
- Job Recording System: Job results, including processing time, input audio URLs, output text URLs, etc., are stored in DynamoDB.
Advanced Batch-Processing Architecture for Massive Transcription
We aimed to adopt a decoupled architecture that provides flexibility in choosing the best and most cost-effective solution for each component in the industry. Simultaneously, we strived to keep the framework components fully managed and serverless to closely simulate the experience of using managed transcription services.
Furthermore, two processes are employed in each node to segregate GPU-bound tasks from I/O and CPU-bound tasks, and fetching the next audio clips earlier while the current one is still being transcribed, allows us to eliminate any waiting period. After one audio clip is completed, the next is immediately ready for transcription. This approach not only reduces the overall processing time for batch jobs but also leads to even more significant cost savings.
We also offer a data exploration tool – Jupyter notebook, designed to assist in preparing and analyzing inference benchmarks for various recognition models running on SaladCloud.
Discover our open-source code for a deeper dive:
Implementation of Inference and Benchmark Worker
Massive Transcription Tests for Whisper Large on SaladCloud:
We launched two container groups on SaladCloud, with each one dedicated to one of the two models.
Each group was configured with 100 replicas (2vCPU and 12 GB RAM with all GPU types with 8GB or more VRAM) in SaladCloud and ran for approximately 10 hours. Here is the comparison:
| 10-hour Transcription with 100 Replicas in SaladCloud | Whisper Large V3 | Distil-Whisper Large V2 |
| Number of Transcribed Audio Files | 2,364,838 | 3,846,559 |
| Total Audio Length (s) | 28,554,156 (8000 hours) | 47,207,294 (13113 hours) |
| Average Audio Length (s) | 12 | 12 |
| Cost on SaladCloud (GPU resource pool) | Around $100 100 Replicas (2vCPU,12GB RAM), 20 GPU types actually used | Around $100 100 Replicas (2vCPU,12GB RAM), 22 GPU types actually used |
| Cost on AWS and Cloudflare (Job queue/Recording system & cloud storage) | Less than $10 | Around $15 |
| Most Cost-Effective GPU Type for transcribing long audio files exceeding 30 seconds | RTX 3060 196 hours per dollar | RTX 2080 Ti 500 hours per dollar |
| Most Cost-Effective GPU Type for transcribing short audio files lasting less than 30 seconds | RTX 2080/3060/3060Ti/3070Ti 47 hours per dollar | RTX 2080/3060 Ti 90 hours per dollar |
| Best-performing GPU Type for transcribing short audio files lasting less than 30 seconds | RTX 4080 Average real-time factor: 40, transcribing 40 seconds of audio per second | RTX 4090 Average real-time factor: 93, transcribing 93 seconds of audio per second |
| Best-Performing GPU Type for transcribing short audio files lasting less than 30 seconds | RTX 3080Ti/4070Ti/4090 Average real-time factor: 8, transcribing 8 seconds of audio per second | RTX 4090 Average real-time factor: 14, transcribing 14 seconds of audio per second |
| System Throughput | Transcribing 793 seconds of audio per second | Transcribing 1311 seconds of audio per second |
Performance evaluation of the two Whisper Large models
Different from those obtained in local tests with a few machines in a LAN, all these numbers are achieved in a global and distributed cloud environment that provides transcription at a large scale, including the entire process from receiving requests to transcribing and sending the responses.
Evidently, Distill-Whisper Large V2 outperforms Whisper Large V3 in both cost and performance. With a model size half that of Whisper, Distill-Whisper can run faster and allow for the utilization of a broader range of GPU types. This significant reduction in cost and improvement in performance are noteworthy outcomes. If the requirement is mainly for English speech recognition, Distill-Whisper is recommended.
While Distil-Whisper boasts a six-fold increase in speed compared to Whisper, the real-world tests indicate that its system throughput is only 165% of that of Whisper. Similar to a car, its top speed depends on factors such as the engine, gears, chassis, and tires. Simply upgrading the engine to one that is 200% more powerful doesn’t assure a doubling of the maximum speed.
In a global and distributed cloud environment offering services at a large scale, various factors can impact overall performance, including distance, transmission and processing delays, model size, and performance, among others. Hence, a comprehensive approach is essential for system design and implementation, encompassing use cases, business goals, resource configuration, and algorithms, among other considerations.
Performance Comparison across Different Clouds
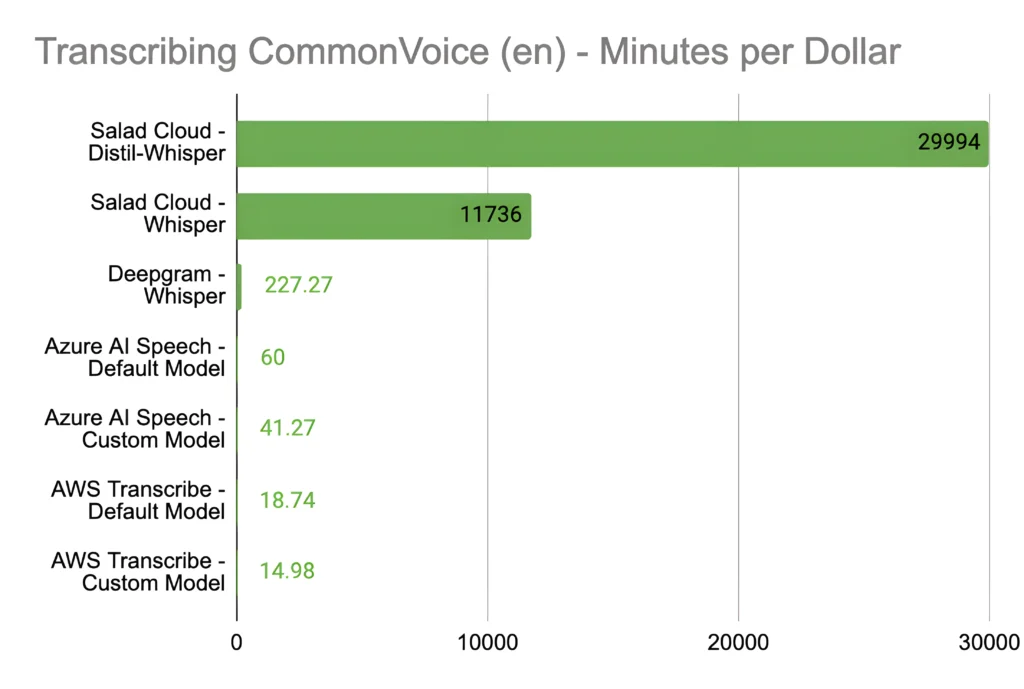
Thanks to the open-source speech recognition model, Whisper Large V3, and the advanced batch-processing architecture harnessing hundreds of consumer GPUs on SaladCloud, we have already achieved a remarkable 500-fold cost reduction while retaining the same level of accuracy as other public cloud providers: $1 dollar can transcribe 11,736 minutes of audio (nearly 200 hours) with the most cost-effective GPU type.
Distil-Whisper Large V2 propels us even further, delivering an incredible 1000-fold cost reduction for English speech recognition compared to managed transcription services. This equates to $1 transcribing 29,994 minutes of audio, or nearly 500 hours. We believe these will fundamentally transform the speech recognition industry.
SaladCloud: The Most Affordable GPU Cloud for Massive Audio Transcription
For voice AI companies in pursuit of cost-effective and robust GPU solutions at scale, SaladCloud emerges as a game-changing solution. Boasting the market’s most competitive GPU prices, it tackles the issues of soaring cloud expenses and constrained GPU availability.
In an era where cost-efficiency and performance take precedence, choosing the right tools and architecture can be transformative. Our recent Inference Benchmark of Whisper Large V3 and Distil-Whisper Large V2 exemplifies the savings and efficiency that can be achieved through innovative approaches. We encourage developers and startups to explore our open-source resources and witness the potential firsthand.


