A cost-effective alternative to Text-to-speech APIs
In the realm of text-to-speech (TTS) technology, two open-source models have recently garnered everyone’s attention: OpenVoice and MetaVoice. Each model has unique capabilities in voice synthesis, but both were recently open sourced. We conducted benchmarks for both models on SaladCloud showing a world of efficiency and cost-effectiveness, highlighting the platform’s ability to democratize advanced voice synthesis technologies. The benchmarks focused on self-managed OpenVoice and MetaVoice as a far cheaper alternative to popular text to speech APIs.
In this article, we will delve deeper into each of these models, exploring their distinctive features, capabilities, price, speed, quality, and how they can be used in real-world applications. Our goal is to provide a comprehensive understanding of these technologies, enabling you to make informed decisions about which model best suits your voice synthesis requirements. If you are serving TTS inference at scale, utilizing a self-managed, open-source model framework on a distributed cloud like SaladCloud is 50-90% cheaper compared to APIs.
Efficiency and affordability of Salad’s distributed cloud
Recently, we benchmarked OpenVoice and MetaVoice on SaladCloud’s global network of distributed GPUS. Tapping into thousands of latent consumer GPUs, SaladCloud’s GPU prices start from $0.02/hour. With more than 1 Million PCs on the network, SaladCloud’s distributed infrastructure provides the computational power needed to process large datasets swiftly, while its cost-efficient pricing model ensures that businesses can leverage these advanced technologies without breaking the bank.
Running OpenVoice on SaladCloud comes out to be 300 times cheaper than Azure Text to Speech service. Similarly, MetaVoice on SaladCloud is 11X cheaper than AWS Polly Long Form.
A common thread: Open Source Text-to-Speech innovation
OpenVoice TTS, OpenVoice Cloning, and MetaVoice share a foundational principle: they are all open-source text-to-speech models. These models are not only free to use but also offer transparency in their development processes. Users can inspect the source code, contribute to improvements, and customize the models to fit their specific needs. With the source code, developers and researchers can customize and enhance these models to suit their specific needs, driving innovation in the TTS domain.
A closer look at each model: OpenVoice and MetaVoice
OpenVoice is an open-source, instant voice cloning technology that enables the creation of realistic and customizable speech from just a short audio clip of a reference speaker. Developed by MyShell.ai, OpenVoice stands out for its ability to replicate the voice’s tone color while offering extensive control over various speech attributes such as emotion and rhythm. OpenVoice voice replication process involves
several key steps that can be used both together or separately:
OpenVoice Base TTS
OpenVoice’s base Text-to-Speech (TTS) engine is a cornerstone of its framework, efficiently transforming written text into spoken words. This component is particularly valuable in scenarios where the primary goal is text-to-speech conversion without the need for specific voice toning or cloning. The ease with which this part of the model can be isolated and utilized independently makes it a versatile tool that is ideal for applications that demand straightforward speech synthesis.
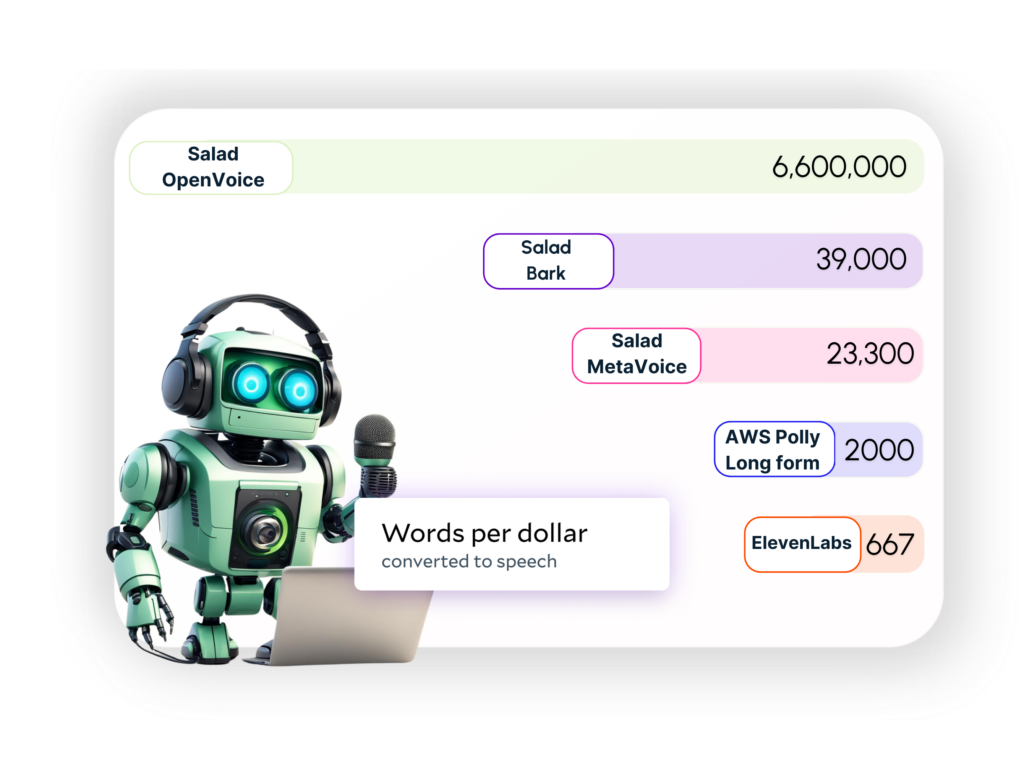
OpenVoice Benchmark: 6 Million+ words per $ on SaladCloud
OpenVoice Cloning
Building upon the base TTS engine, this feature adds a layer of sophistication by enabling the replication of a reference speaker’s unique vocal characteristics. This includes the extraction and embodiment of tone color, allowing for the creation of speech that not only sounds natural but also carries the emotional and rhythmic nuances of the original speaker. OpenVoice’s cloning capabilities extend to zero-shot cross-lingual voice cloning, a remarkable feature that allows for the generation of speech in languages not present in the training dataset. This opens up a world of possibilities for multilingual applications and global reach.
MetaVoice-1B
MetaVoice-1B is a robust 1.2 billion parameter base model trained on an extensive dataset of 100,000 hours of speech. Its design is focused on achieving natural-sounding speech with an emphasis on emotional rhythm and tone in English. A standout feature of MetaVoice 1B is its zero-shot cloning capability for American and British voices, requiring just 30 seconds of reference audio for effective replication. The model also supports cross-lingual voice cloning with fine-tuning, showing promising results with as little as one minute of training data for Indian speakers. MetaVoice-1B is engineered to capture the nuances of emotional speech, ensuring that the synthesized output resonates with listeners on a deeper level.
MetaVoice Benchmark: 23,300 words per $ on SaladCloud
Benchmark results: Price comparison of voice synthesis models on SaladCloud
The following table presents the results of our benchmark tests, where we ran the models OpenVoice TTS, OpenVoice Cloning, and MetaVoice on SaladCloud GPUs. For consistency, we used the text from Isaac Asimov’s book “Robots and Empire”, available on Internet Archive: Digital Library of Free & Borrowable Books, Movies, Music & Wayback Machine , comprising approximately 150,000 words, and processed it through all compatible SaladCloud GPUs.
| Model Name | Most Cost-Efficient GPU | Words per Dollar | Second Most Cost Efficient GPU | Words per Dollar |
|---|---|---|---|---|
| OpenVoice TTS | RTX 2070 | 6.6 Million | GTX 1650 | 6.1 million |
| OpenVoice Cloning | GTX 1650 | 4.7 Million | RTX 2070 | 4.02 million |
| MetaVoice | RTX 3080 | 23,300 | RTX 3080 Ti | 15,400 |
The benchmark results clearly indicate that OpenVoice, both in its TTS and Cloning variants, is significantly more cost-effective compared to MetaVoice. The OpenVoice TTS model, when run on an RTX 2070 GPU, achieves an impressive 6.6 Million words per dollar, making it the most efficient option among the tested models. The price of using RTX2070 on SaladCloud is $0.06/hour, which, together with the vCPU and RAM we used, got us to a total of $0.072/hour.
OpenVoice Cloning also demonstrates strong cost efficiency, particularly when using the GTX 1650, which processes 4.7 Million words per dollar. This is a notable advantage for applications requiring less robotic voice.
In contrast, MetaVoice’s performance on the RTX 3080 and RTX 3080 Ti GPUs yields significantly fewer words per dollar, indicating a higher cost for processing speech. However, don’t rush to dismiss MetaVoice just yet; upcoming comparisons may offer a different perspective that could sway your opinion.
Benchmark results: Processing speed comparison
While price is a crucial factor, there are scenarios where processing speed takes precedence. To prepare for these situations, we also compared the processing speeds of the OpenVoice TTS, OpenVoice Cloning, and MetaVoice models on SaladCloud GPUs.
| Model Name | Fastest GPU | Words per Second |
|---|---|---|
| OpenVoice TTS | RTX 3080 Ti | 230.4 |
| OpenVoice Cloning | RTX 3090 Ti | 200 |
| MetaVoice | RTX 4090 | 1.25 |
The processing speed comparison reveals a stark contrast between the models. OpenVoice TTS and OpenVoice Cloning demonstrate impressive speeds, with the RTX 3080 Ti and RTX 3090 Ti GPUs achieving 230.4 and 200 words per second, respectively. These speeds are well-suited for applications requiring rapid voice synthesis, such as real-time voice assistants or dynamic content generation.
On the other hand, MetaVoice’s performance on the RTX 4090 GPU is significantly slower, with only 1.25 words per second. This reduced speed might be a drawback for time-sensitive applications but could be acceptable for scenarios where the utmost accuracy and quality are paramount, and processing time is less of a concern.
Models Limitations
When benchmarking OpenVoice TTS and MetaVoice on SaladCloud, we observed certain limitations that users should be aware of:
OpenVoice TTS demonstrated remarkable flexibility in our tests, running efficiently on even the lowest vRAM GPUs available on SaladCloud. The model did not exhibit any specific hardware limitations, and we achieved impressive results across the board. To enhance efficiency, we segmented the text into chunks of approximately 30 sentences, but this was a choice for optimization rather than a requirement imposed by the model.
OpenVoice Cloning: Encountered compatibility issues with 40x series GPUs due to CUDA version and library incompatibilities, but these are expected to be resolved.
MetaVoice: According to MetaVoice’s official documentation, the model requires GPUs with at least 12GB of vRAM. In our tests, we successfully ran MetaVoice on 10GB GPUs, but we could not extend this to lower-capacity GPUs. Additionally, we faced a limitation in token processing, which necessitated breaking the text into individual sentences for separate processing. Also, note that processing the same text through the same model might return quite different results.
Quality comparison for the Text-to-Speech models
In our quest to evaluate the quality of voice synthesis models, we chose to use the first chapter of the first Harry Potter book as our reference text. The idea was to explore how various well-known personalities, including Donald Trump, Benedict Cumberbatch, Joe Biden, and others, would sound reading the same passage from a beloved children’s book. For OpenVoice TTS, we utilized the default speaker provided by the model. For OpenVoice Cloning and MetaVoice, we used identical reference audio files, which were all snippets ranging from 30 seconds to 1 minute, extracted from audiobooks, interviews, and public speeches.
It’s important to note that for MetaVoice, it would be much better to use a reference voice that matches the target speech type. For example, when aiming to read a book, using a sample from an audiobook is preferable, as it ensures a closer match in terms of pauses and tone. We did not do that for our comparison to keep similar conditions for both models.
You can listen to the quality comparisons here.
As you can hear, MetaVoice emerged as a standout performer in terms of quality. Despite not undertaking any additional fine-tuning, such as adjusting pauses or ensuring phrase continuity, the results are astonishingly impressive. We are confident that with some minor tweaks and enhancements, MetaVoice’s voice cloning capabilities could achieve near-perfection.
Although MetaVoice lagged behind OpenVoice in speed and cost-effectiveness, it delivers superior audio quality. This suggests that MetaVoice could be the preferred choice for applications where quality is paramount.
As for OpenVoice, it’s important to note that, according to its official documentation, the model primarily clones the tone of voice but not the accent or other vocal features. However, OpenVoice does offer additional features, such as rhythm and emotion adjustments, which we did not modify from their default settings in this comparison. Utilizing these fine-tuning options could potentially bring OpenVoice’s output closer to the original reference voices, enhancing its overall performance.
Balancing quality, speed, and price
Our comprehensive analysis of MetaVoice and OpenVoice has revealed distinct strengths and trade-offs between these models. Here’s a summary of our findings:
Quality: MetaVoice takes the lead with its stunning voice cloning quality, producing results that are remarkably close to the original references. Its ability to replicate the nuances of famous voices with minimal input is unmatched. OpenVoice, while not as precise in cloning accents or unique vocal features, offers commendable quality, especially when its rhythm and emotion features are fine-tuned.
Speed: OpenVoice shines in processing speed, making it an excellent choice for applications that require rapid voice synthesis, such as real-time voice assistants or dynamic content generation. MetaVoice’s slower processing speed may be a drawback for time-sensitive applications but could be acceptable for scenarios where the utmost accuracy and quality are paramount.
Price: OpenVoice stands out as the more cost-effective option, offering impressive words-per-dollar efficiency. This makes it particularly suitable for large-scale text-to-speech processing where budget constraints are a consideration. MetaVoice, while more expensive, may justify its higher cost with its superior quality in voice cloning.
Suggested Use Cases for Each Model:
MetaVoice: Ideal for projects where quality trumps all other factors, such as producing audiobooks narrated by celebrity voices, high-end voiceovers for documentaries, or premium virtual assistants.
OpenVoice TTS: Best suited for applications requiring fast and cost-effective text-to-speech conversion, such as reading news articles, generating navigation prompts, or providing accessibility features when the voice itself does not matter.
OpenVoice Cloning: A great option for scenarios needing customized voice toning without exact accent replication, like personalized chatbot responses, dynamic video game content, or instructional videos.
Self-managed, open-source models over text-to-speech APIs
While the current shortage for high-end GPUs has led to high prices and wait-times, distributed & community clouds like SaladCloud have unlocked 1000s of Text-to-Speech compatible consumer GPUs. With no infrastructure cost and 1000s of GPUs available, prices are very low compared to high-end GPUs.
Text to speech APIs provide an elegant solution for serving TTS inference without sinking development time or hunting down compute. But at scale, the economics of text to speech APIs breaks down, especially when companies can take advantage of the really low prices of consumer GPUs on clouds like SaladCloud.
With self-managed OpenVoice, companies get 4 Million to 6 Million words per dollar. Self-managed MetaVoice delivers 23,300 words per dollar. The closest text to speech API in terms of cost-performance is AWS Polly Long Form, delivering 2000 words per dollar and ElevenLabs at 667 words per dollar.
It is prudent for Voice AI companies to carefully look into their use cases and determine where open-source models will work. With a week or two of extra development time, companies can then save up to 90% in TTS inference as they scale.