
Stable Diffusion XL (SDXL) Benchmark
A couple months back, we showed you how to get almost 5000 images per dollar with Stable Diffusion 1.5. Now, with the release of Stable Diffusion XL, we’re fielding a lot of questions regarding the potential of consumer GPUs for serving SDXL inference at scale. The answer from our Stable Diffusion XL (SDXL) Benchmark is a resounding yes.
In this benchmark, we generated 60.6k hi-res images with randomized prompts on 39 nodes equipped with RTX 3090 and RTX 4090 GPUs. We saw an average image generation time of 15.60s at a per-image cost of $0.0013.
At 769 SDXL images per dollar, consumer GPUs on Salad’s distributed cloud are still the best bang for your buck for AI image generation, even when enabling no optimizations on SaladCloud and all optimizations on AWS.
Architecture
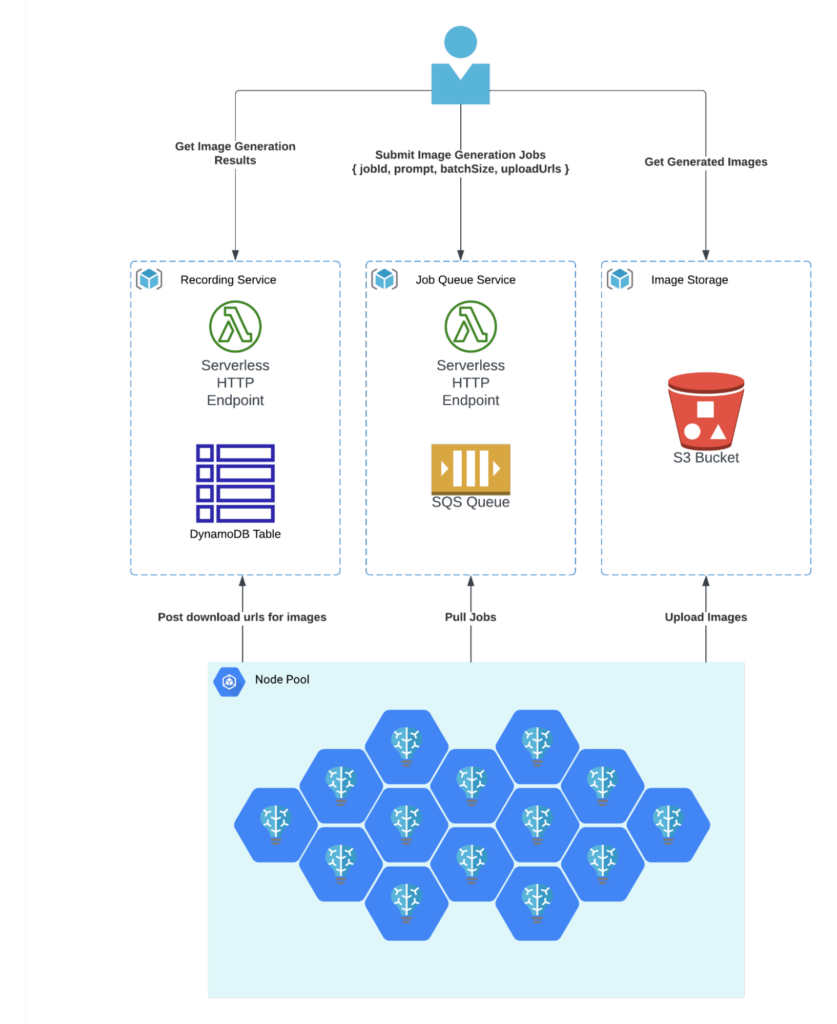
We used an inference container based on SDNext, along with a custom worker written in Typescript that implemented the job processing pipeline. The worker used HTTP to communicate with both the SDNext container and with our batch framework.
Our simple batch-processing framework comprises:
- Storage: Image files stored in AWS S3.
- Queue System: Jobs are queued via AWS SQS, with unique identifiers and pre-signed URLs to upload the generated images.
- Result Storage: After images are generated and uploaded, download URLs for each job are stored in DynamoDB.
- Worker Coordination: We integrated HTTP handlers using AWS Lambda so workers could have easy access to the queue and table.
Discover our open-source code for a deeper dive:
- Job Queue Service
- Recording Service
- SDXL Benchmark Worker – Docker Image
- SDNext Preloaded with SDXL – Docker Image
- SDNext Base Image – Docker Image
Deployment on SaladCloud
We set up a container group targeting nodes with 4 vCPUs, 32GB of RAM, and GPUs with 24GB of vram, which includes the RTX 3090, 3090 ti, and 4090.
We filled a queue with randomized prompts in the following format:
`a ${adjective} ${salad} salad on a ${servingDish} in the style of ${artist}`
We used ChatGPT to generate roughly 100 options for each variable in the prompt and queued up jobs with 4 images per prompt. SDXL is composed of two models, a base and a refiner. We generated each image at 1216 x 896 resolution, using the base model for 20 steps and the refiner model for 15 steps. You can see the exact settings we sent to the SDNext API.
Results – 60,600 Images for $79
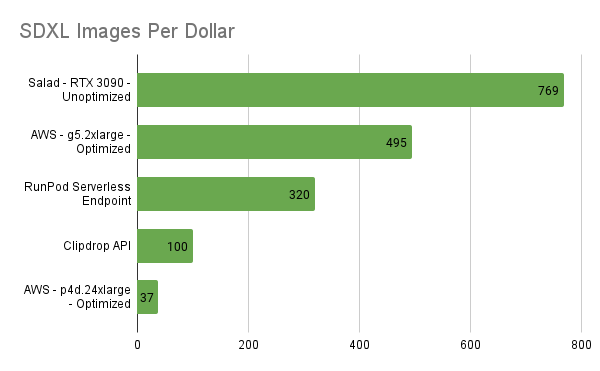
Over the benchmark period, we generated more than 60k images, uploading more than 90GB of content to our S3 bucket, incurring only $79 in charges from SaladCloud, which is far less expensive than using an A10g on AWS, and orders of magnitude cheaper than fully managed services like the Stability API. We did see slower image generation times on consumer GPUs than on data center GPUs, but the cost differences give SaladCloud the edge. While an optimized model on an A100 did provide the best image generation time, it was by far the most expensive per image of all methods evaluated.


Grab a fork and see all the salads we made here on our GitHub page.
Future Improvements
For comparison with AWS, we gave them several advantages that we did not implement in the container we ran on SaladCloud. In particular, torch.compile isn’t practical on SaladCloud because it adds 40+ minutes to the container’s start time, and Salad’s nodes are ephemeral. However, such a long start time might be an acceptable tradeoff in a datacenter context with dedicated nodes that can be expected to stay up for a very long time, so we did use torch.compile on AWS.
Additionally, we used the default fp32 variational autoencoder (vae) in our SaladCloud worker, and an fp16 vae in our AWS worker, giving another performance edge to the legacy cloud provider. Unlike re-compiling the model at start time, including an alternate vae is something that would be practical to do on SaladCloud, and is an optimization we would pursue in future projects.
SaladCloud – Still The Best Value for AI/ML Inference at Scale
SaladCloud remains the most cost-effective platform for AI/ML inference at scale. The recent benchmarking of Stable Diffusion XL further highlights the competitive edge this distributed cloud platform offers, even as models get larger and more demanding.

Shawn Rushefsky is a passionate technologist and systems thinker with deep experience across a number of stacks. As Generative AI Solutions Architect at Salad, Shawn designs resilient and scalable generative ai systems to run on our distributed GPU cloud. He is also the founder of Dreamup.ai, an AI image generation tool that donates 30% of its proceeds to artists.


