
Benchmarking Stable Diffusion v1.5 across 23 consumer GPUs
What’s the best way to run inference at scale for stable diffusion? It depends on many factors. In this Stable Diffusion (SD) benchmark, we used SD v1.5 with a controlnet to generate over 460,000 fancy QR codes. The benchmark was run across 23 different consumer GPUs on SaladCloud. Here, we share some of the key learnings for serving Stable Diffusion inference at scale on consumer GPUs.
The Evaluation
For each GPU type, we compared 4 different backends, 3 batch sizes (1, 2, 4), and 2 resolutions (512×512, 768×768), generating images at 15 steps and at 50 steps. Our time measurements include the time taken to generate the image and return it to another process running on localhost. However, we do not include the time taken to generate the base QR code, upload images, or fetch new work from the queue. We recommend handling these tasks asynchronously in order to maximize GPU utilization.
Our cost numbers are derived from the SaladCloud Pricing Calculator, using 2 vCPU and 12 GB of RAM. Costs do not include storage, data transfer, queueing, database, etc. However, these things only cost $2 total for the entire project. We used DreamShaper 8 along with the QR Code Monster controlnet to generate the images with the Euler Ancestral scheduler/sampler.
Cold Start Time
We also evaluated cold start time for the various backends, which measures the time from when a container starts to when it is ready to serve inference. However, it does not include the time required to download the image to the host. For each backend, we chose the average cold start time from the GPU in which it had the best cold start time.
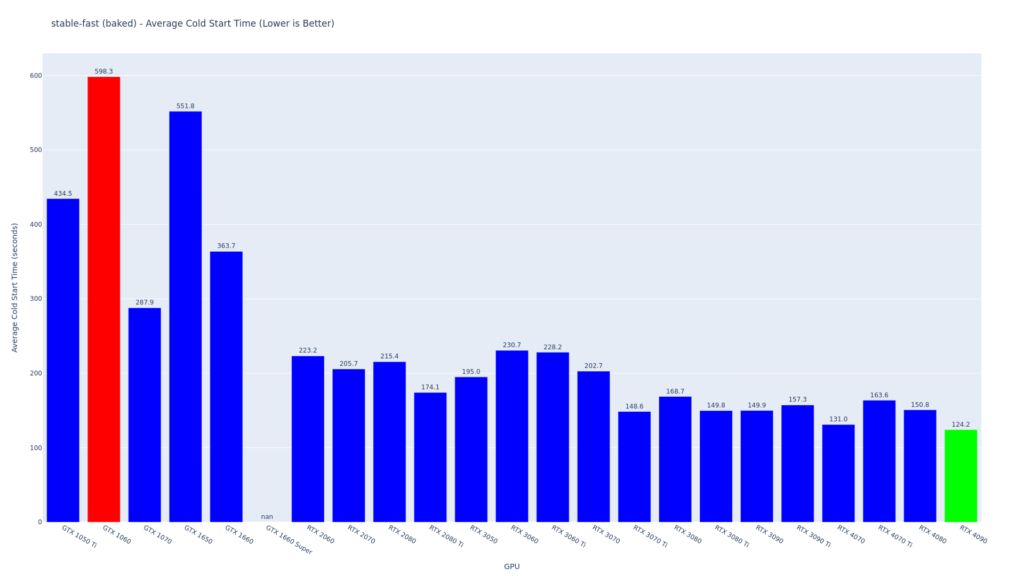
For the stable-fast backend, with the models included in the container, the RTX 4090 has the best average cold start time, while the GTX 1660 has the worst. The empty spot for GTX 1660 Super indicates that no nodes successfully started.
Architecture
We used our standard batch processing architecture that we’ve used for many other benchmarks.
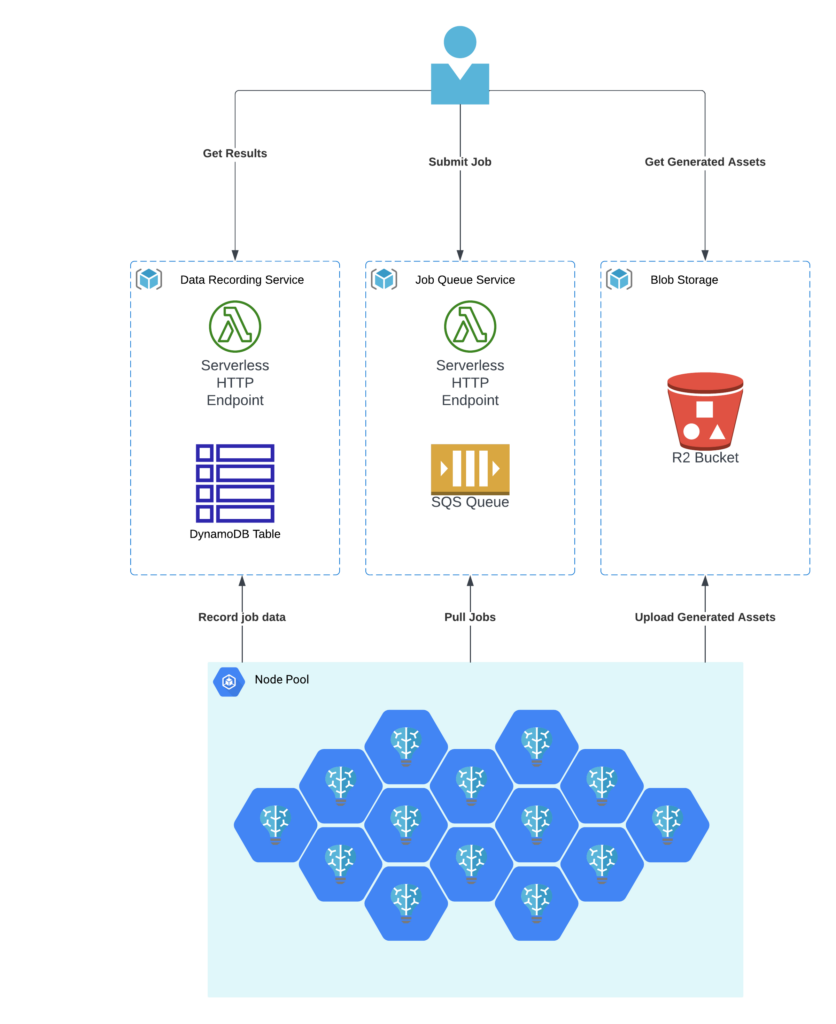
The Backends
stable-fast-qr-code

- Size without models: 2.88 GB
- Size with models: 6.04 GB
- Best Avg Cold Start Time: 124.2s on RTX 4090
This is the only custom backend we used for this benchmark. It uses 🤗 Diffusers with stable-fast. You’ll see in the results that it performed extremely well, almost always taking the top spot for performance and cost performance. However, there are important caveats to consider before choosing to deploy this or any other custom backend.
stable-fast adds a compilation step on start, which can take multiple whole minutes longer than startup for the other backends. Additionally, it achieves the best performance by locking image size at start. For many image generation use cases, dynamic sizing is too important, so this would not be feasible. For other use cases, such as this one where we bulk generated fancy QR codes, it’s ideal. Other build-vs-buy factors should also be taken into consideration.
Automatic1111

- Size without models: 3.13 GB
- Size with models: 5.61 GB
- Best Avg Cold Start Time: 40.7s on RTX 3090 Ti
While designed and built as a user interface for running stable diffusion on your own PC, Automatic1111 is also a very popular inference backend for many commercial SD-powered applications. It boasts wide model and workflow compatibility, is very extensible, and shows strong performance in most categories.
Comfy UI

- Size without models: 4.03 GB
- Size with models: 6.48 GB
- Best Avg Cold Start Time: 15.5s on RTX 4090
ComfyUI is another popular user interface for stable diffusion, but it has a node-and-link-based interface that mimics the underlying components of a workflow. It is the most customizable of the backends, and it has some caching features that are beneficial when not all parameters change between generations.
Stable Diffusion v1.5 Benchmark: Results
Stable Fast is the clear winner here, both in terms of speed and cost. However, while the performance is impressive, building and maintaining a custom backend comes with a lot of additional challenges vs using one of the highly flexible, community-maintained options. In particular, if you’ve already built your solution using one of these off-the-shelf options, you likely do not want to refactor your entire codebase around a new backend. We’ve included some results that exclude Stable Fast for those of you in this situation.
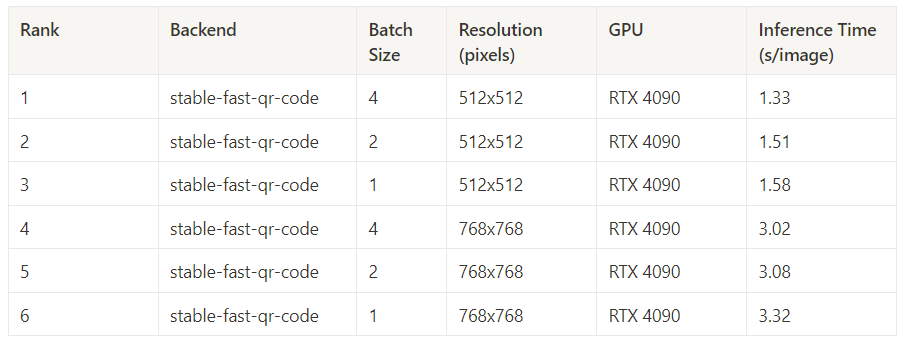
Best Inference Time (15 steps)
With an impressive 27.3 steps/second, Stable Fast achieved outstanding performance on the RTX 4090, generating batches of 4 512×512 images.
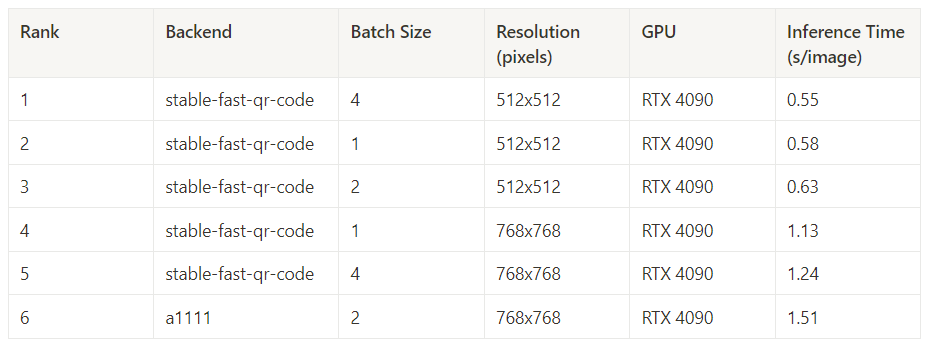
Best Inference Time (50 Steps)
With a 50-step generation, Stable Fast performed even better, achieving 37.6 steps per second on batches of 4 512×512 images.
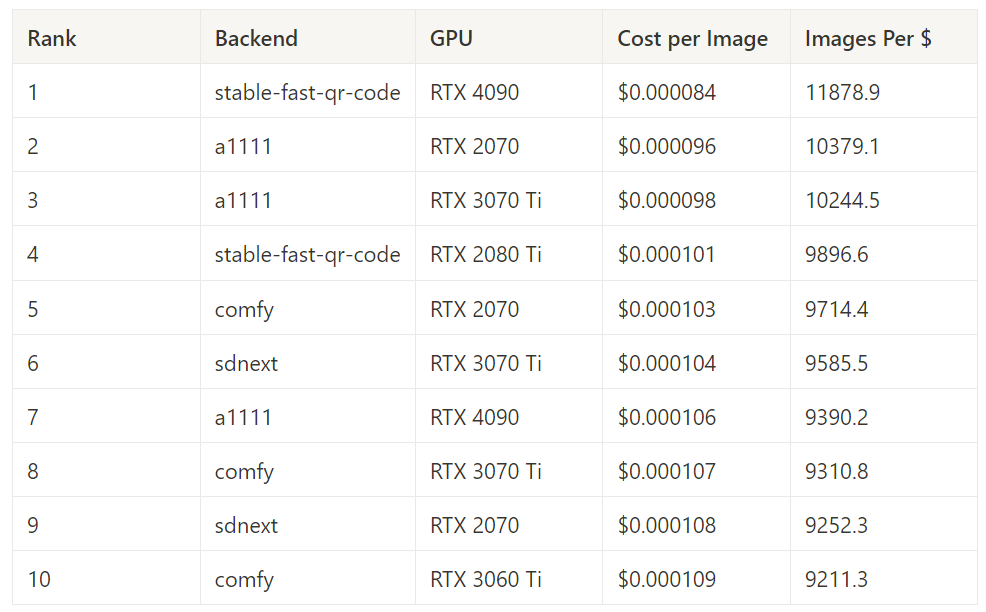
Best Cost Performance – 15 Steps
This measures performance for a given combination of backend+gpu on all 15-step image generation tasks. This includes all batch sizes and image sizes.
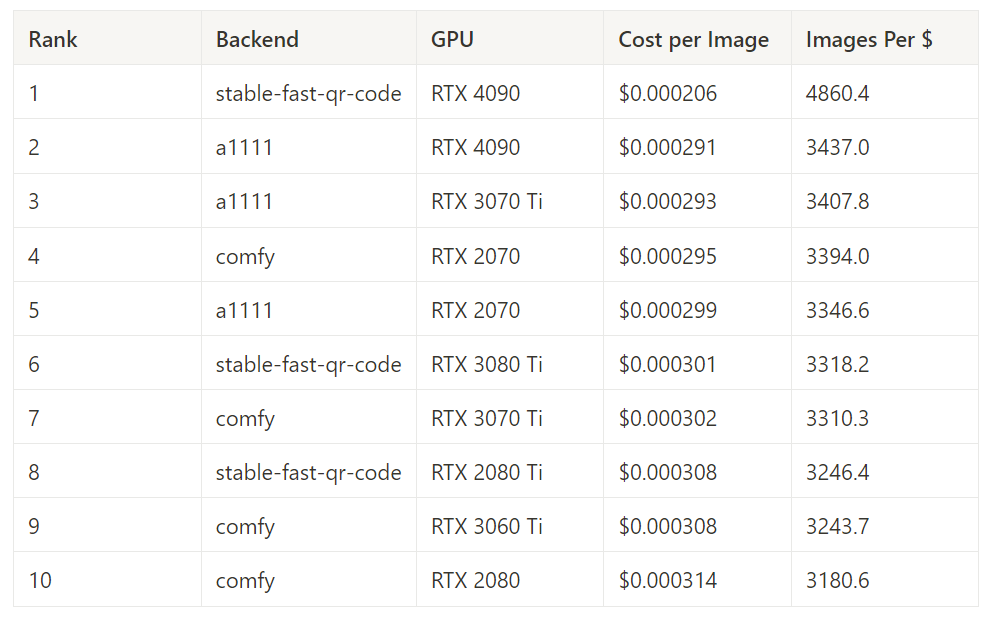
Best Cost Performance – 50 Steps
This measures performance for a given combination of backend and gpu on all 50-step image generation tasks. This includes all batch sizes and image sizes.
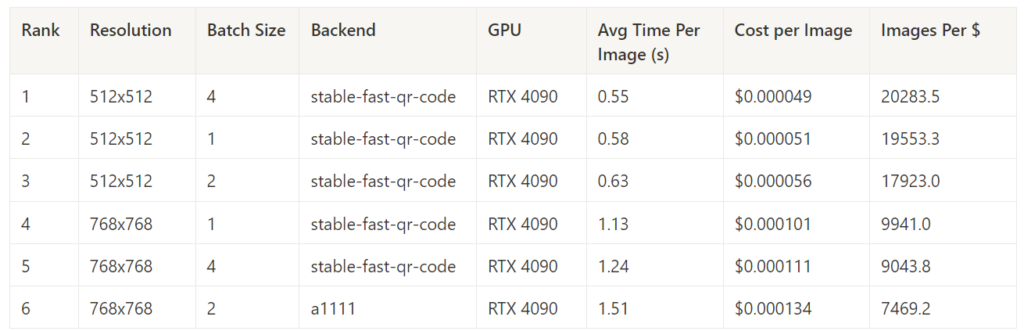
Best Inference Time in Each Task – 15 Steps
This measures the average inference time at each resolution and batch size, with 15 steps.
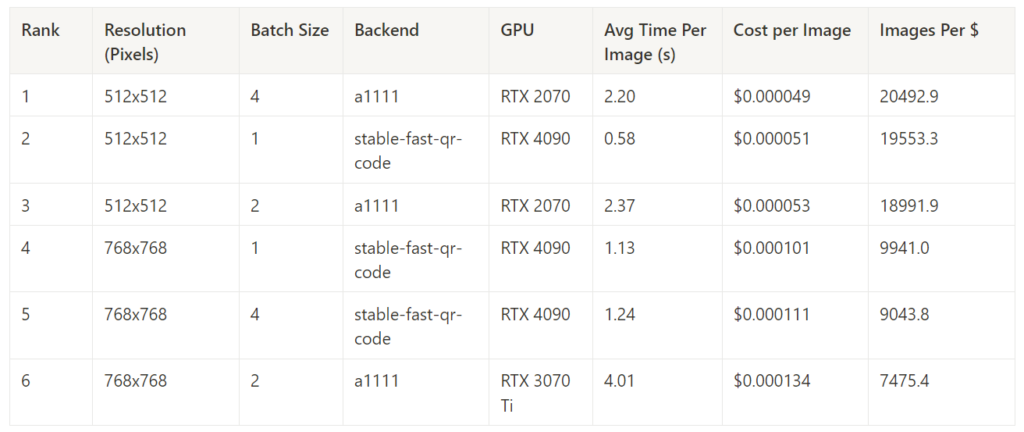
Best Cost Performance in Each Task – 15 Steps
While Stable Fast offered the best overall performance and the best overall cost performance, it was not the absolute best in all tasks for 15-step generations, sharing that honor with Automatic1111. It’s worth noting that A1111 achieved impressive cost-performance results on much lower-end hardware, which may be significantly easier to source.
Best Inference Time in Each Task – 50 Steps
This measures the average inference time at each resolution and batch size, with 50 steps.
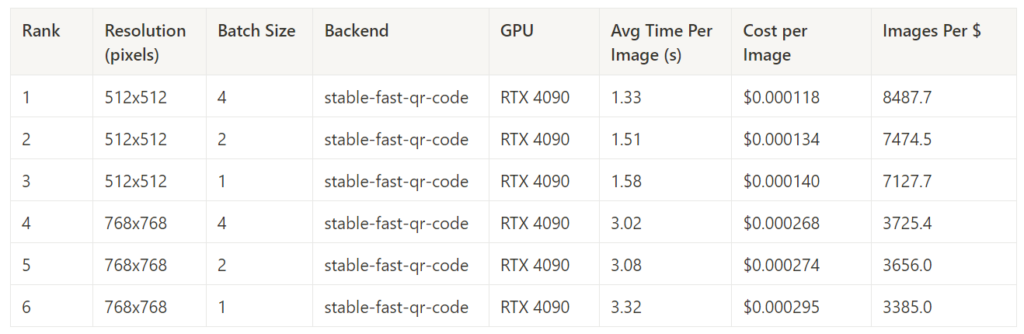
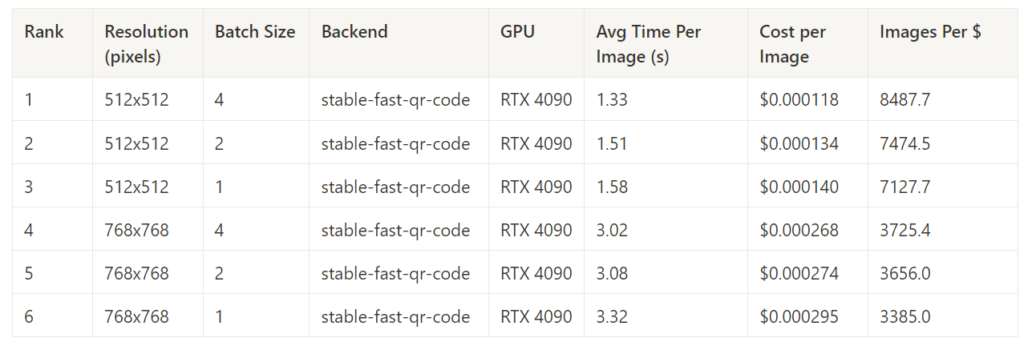
Best Cost Performance in Each Task – 50 Steps
Stable Fast absolutely dominated the 50-step generation tasks, taking a comfortable first place in all categories.
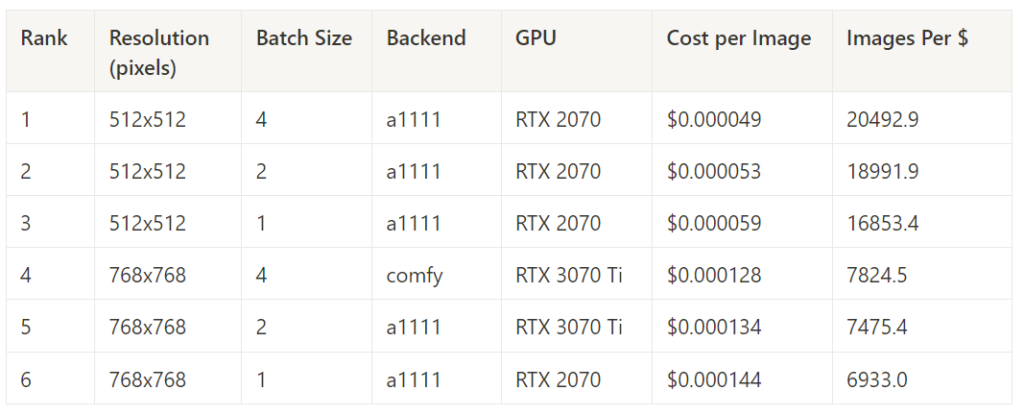
Best Cost Performance in Each Task (no stable-fast) – 15 Steps
Here, we pull Stable Fast out of the results to compare the rest.
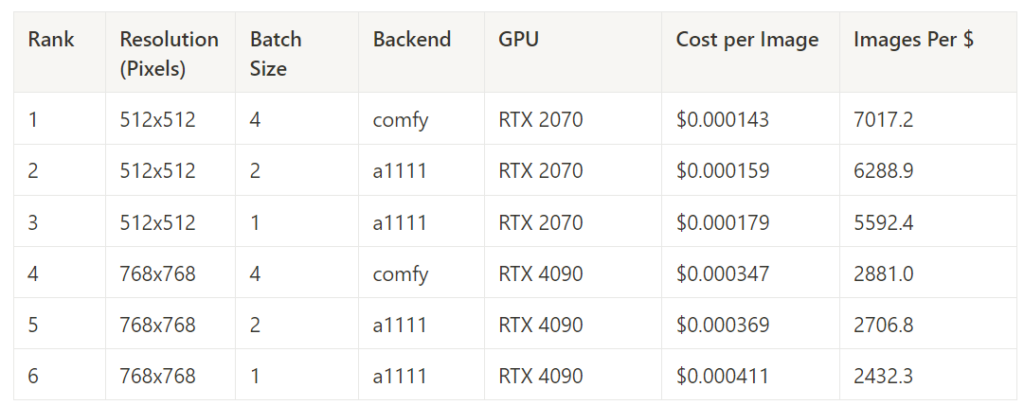
Best Cost Performance in Each Task (no stable-fast) – 50 Steps
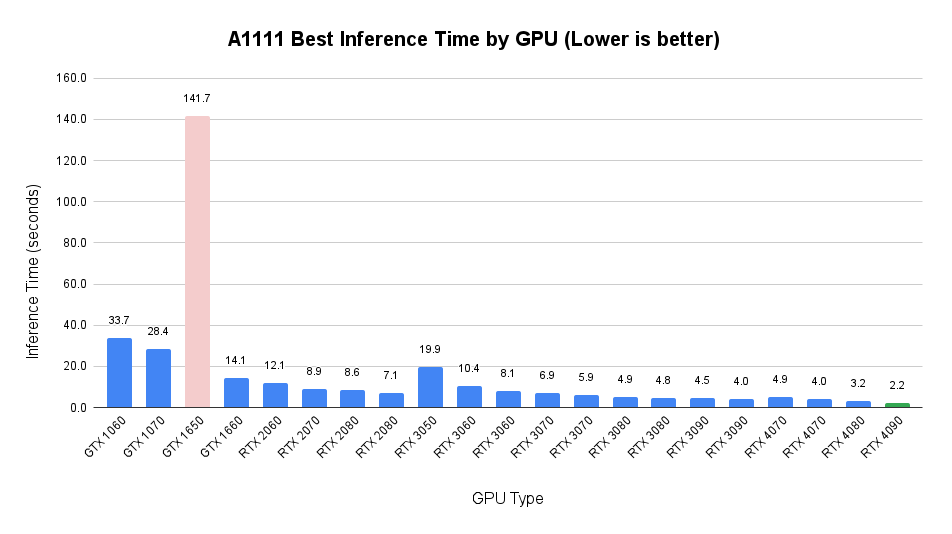
A1111 – Best Inference Time by GPU
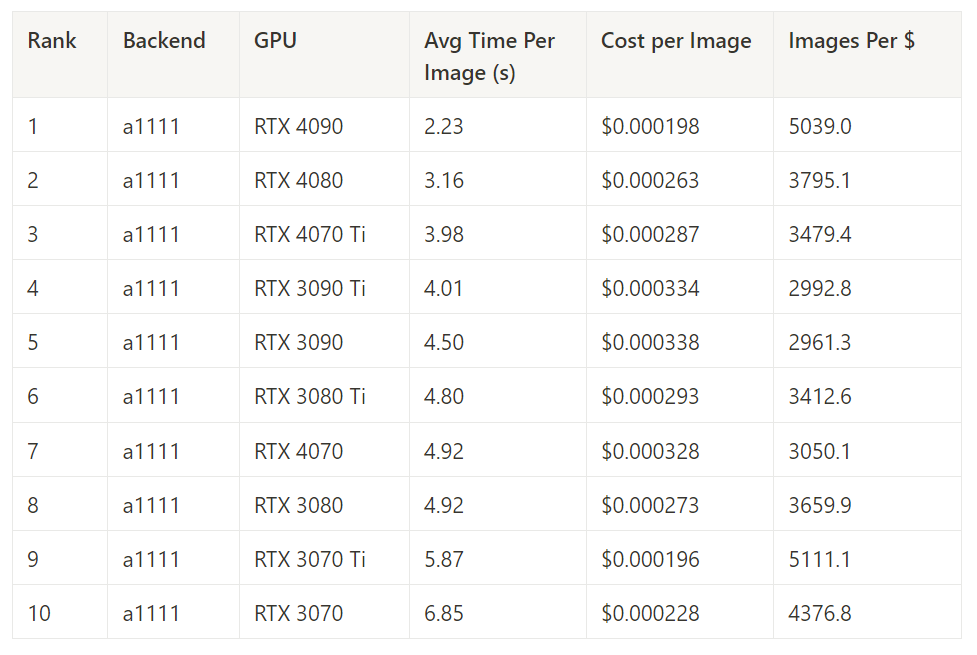
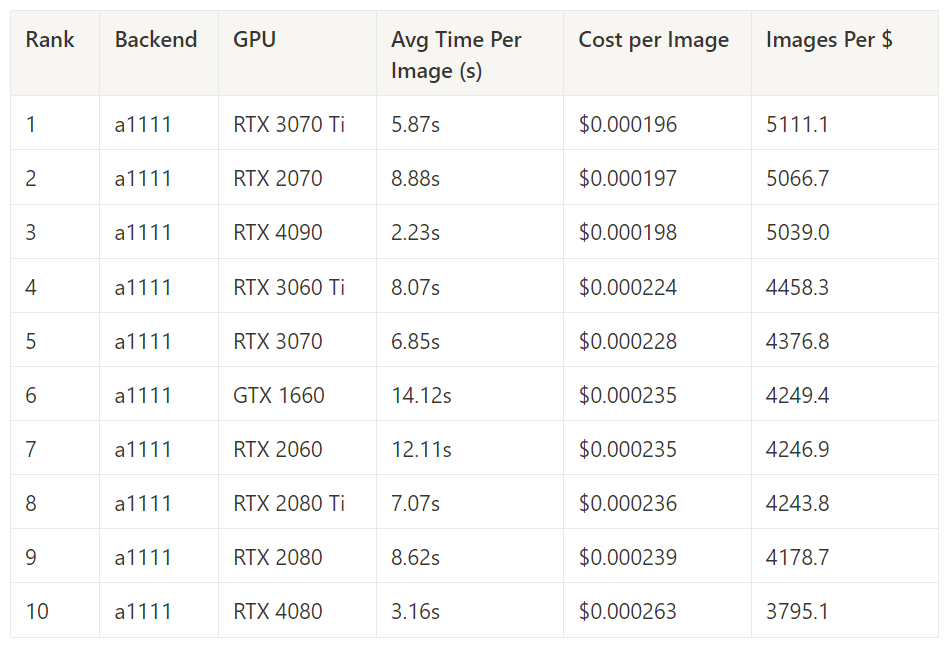
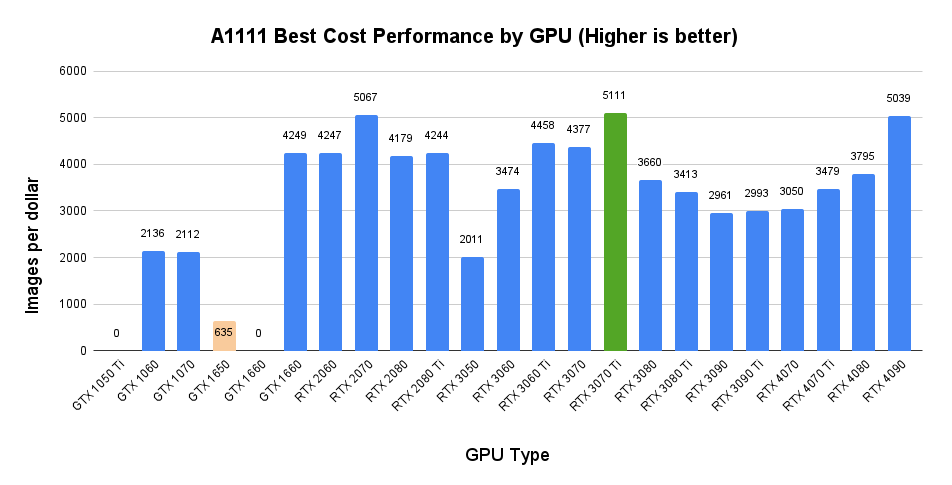
A1111 – Best Cost Performance by GPU
This measures the cost performance of Automatic1111 across all image generation tasks for each GPU.
SD.Next – Best Inference Time By GPU
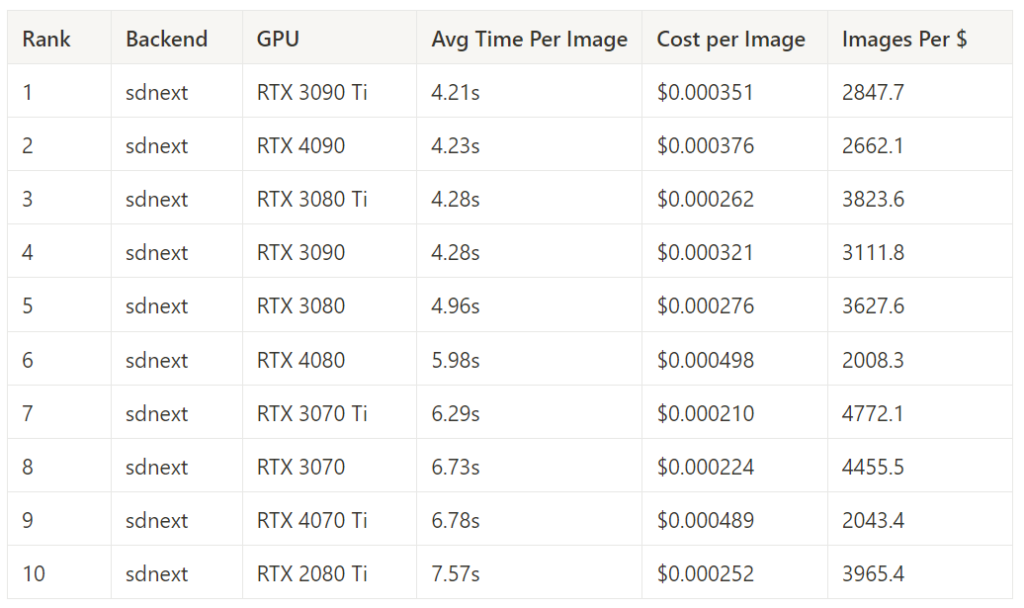
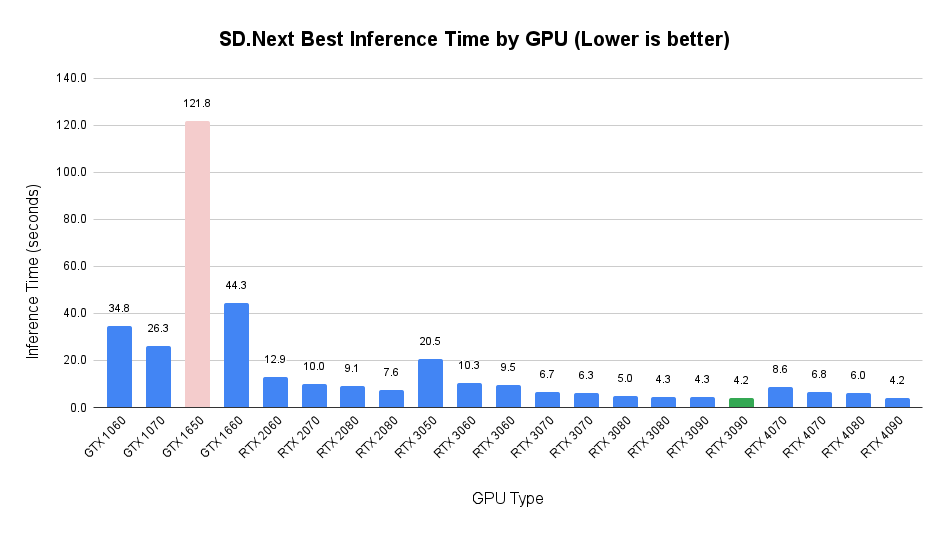
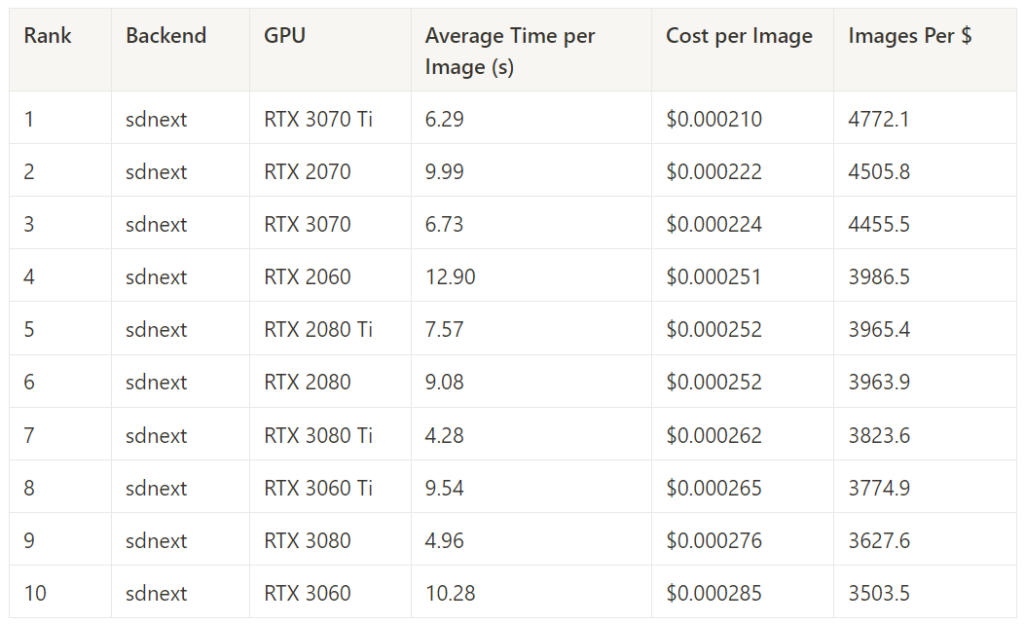
SD.Next – Best Cost Performance by GPU
This measures the cost performance of SD.Next across all image generation tasks, for each GPU.
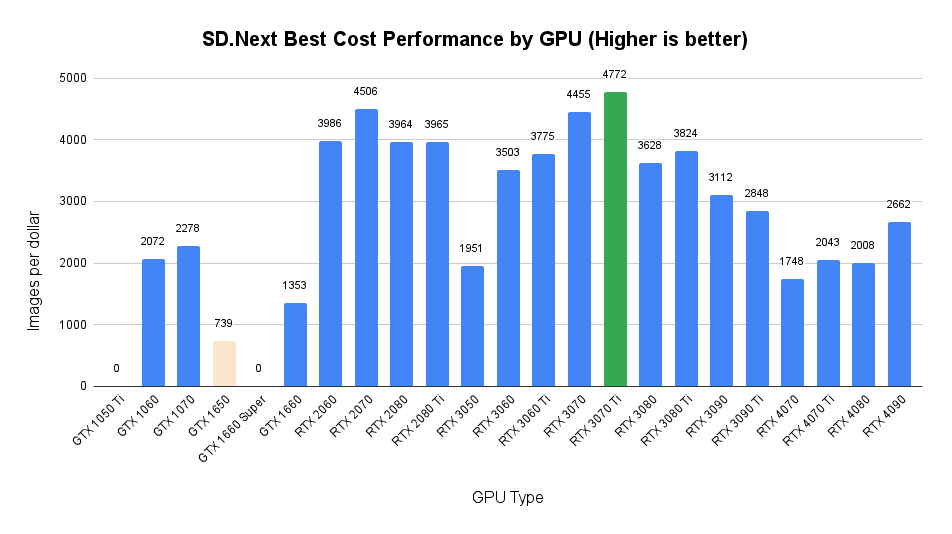
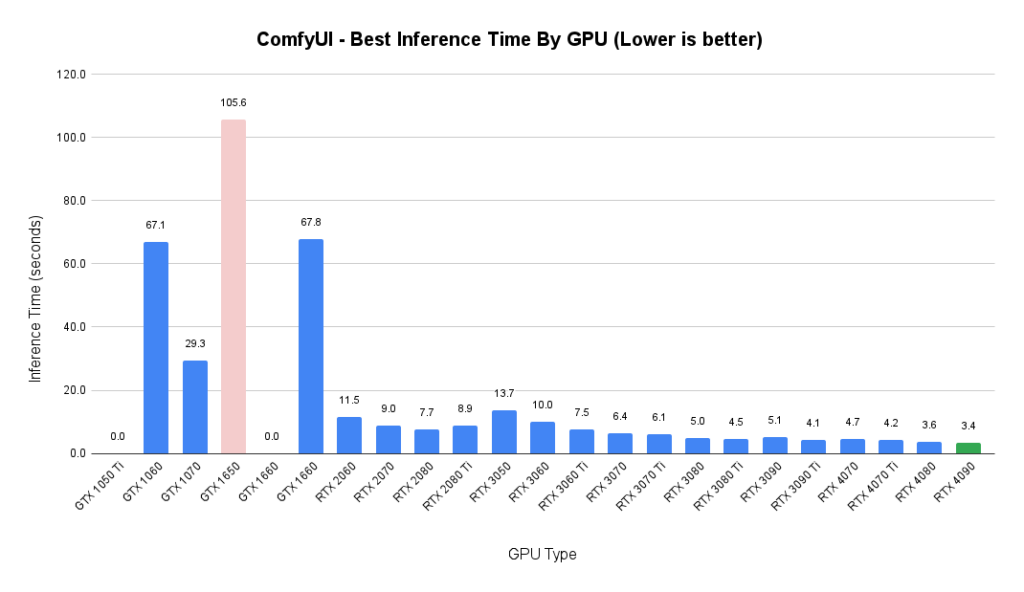
ComfyUI – Best Inference Time By GPU
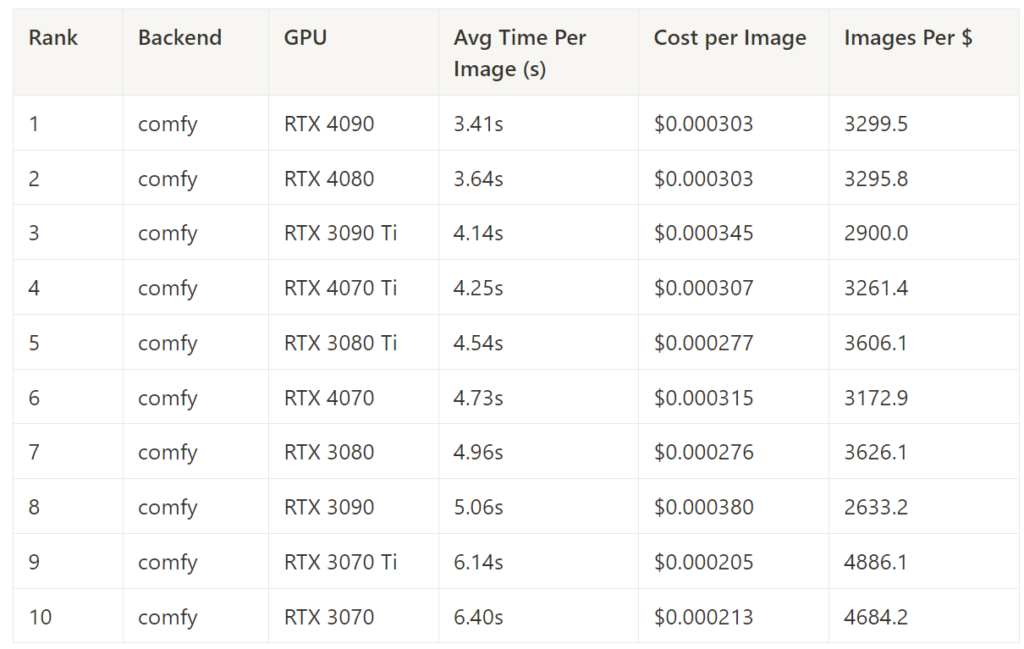
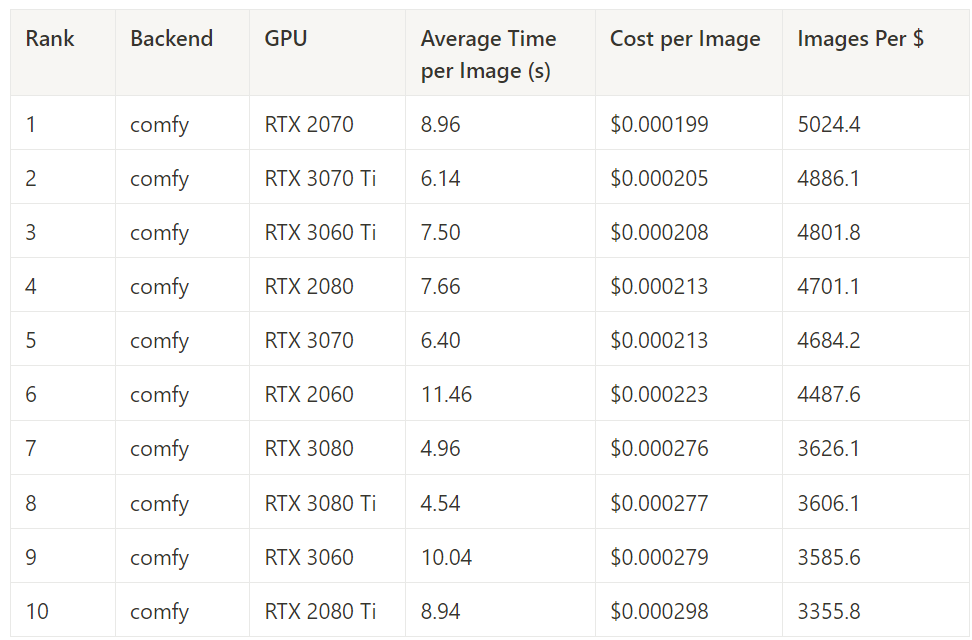
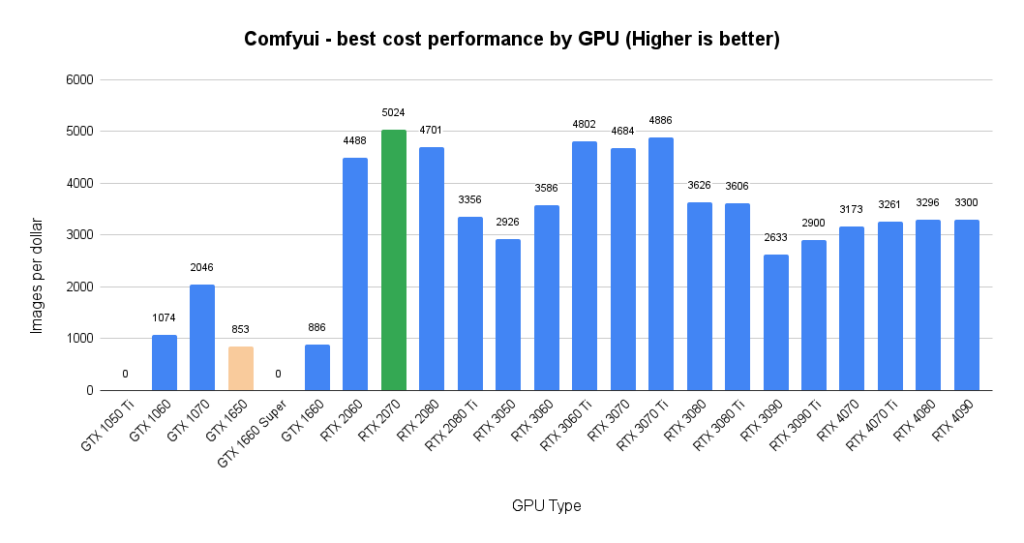
Comfy UI – Best Cost Performance by GPU
This measures the cost performance of Comfy UI across all image generation tasks for each GPU.
Stable Fast – Best Inference Time by GPU
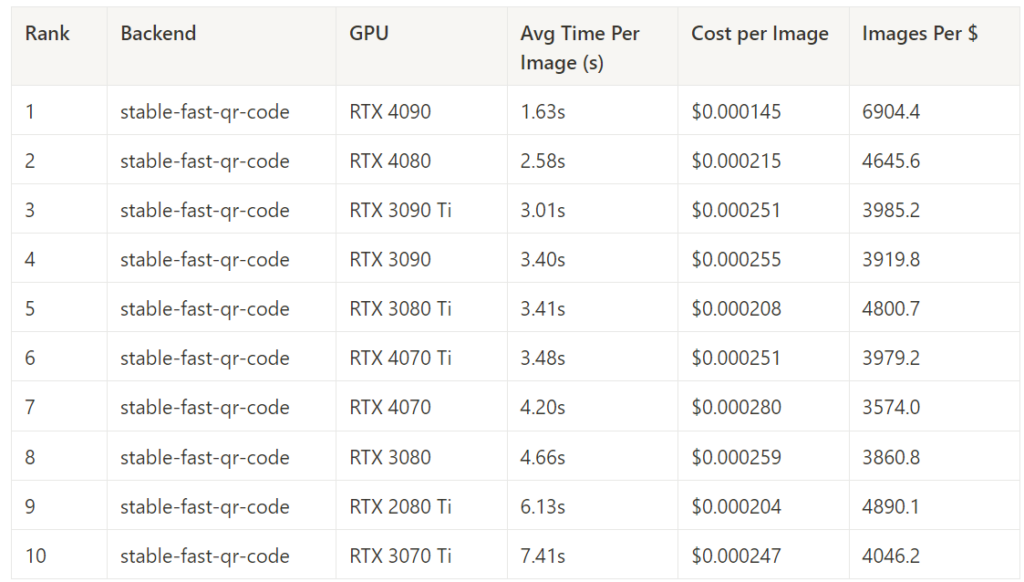
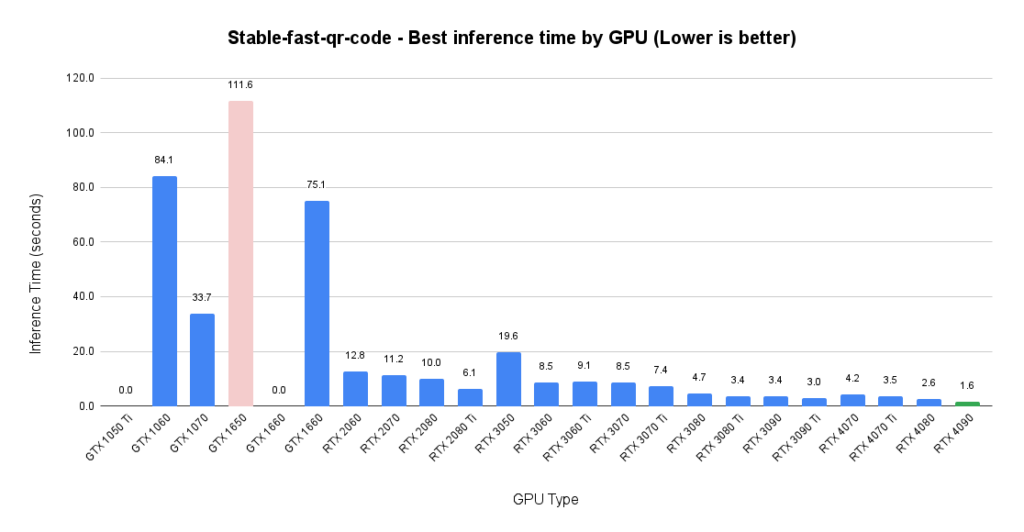
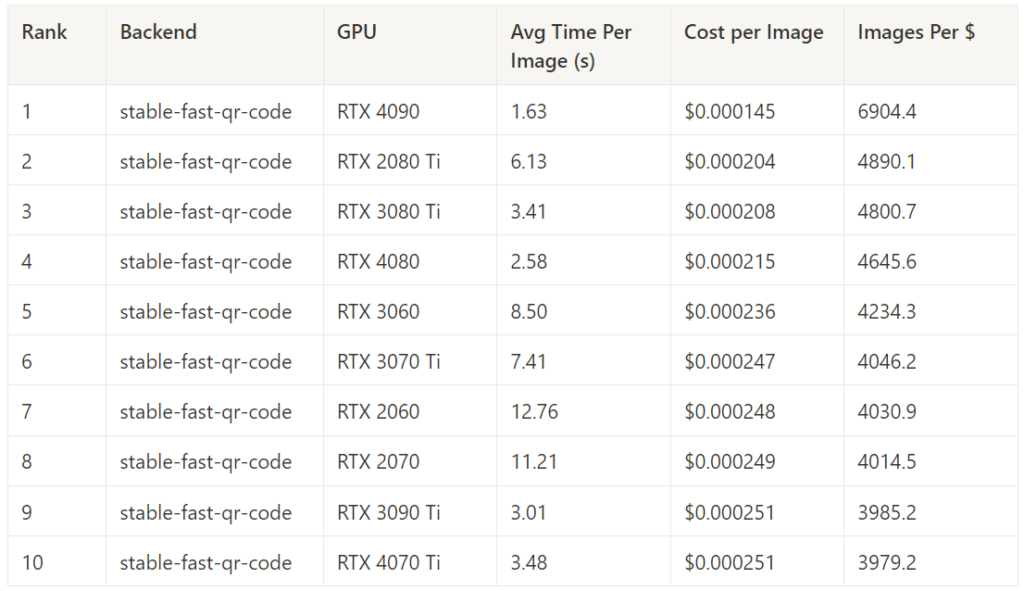
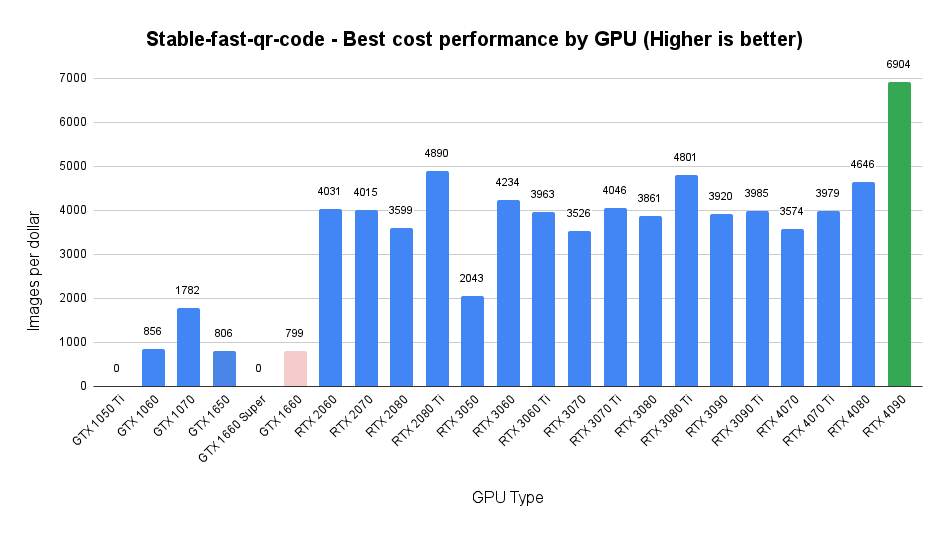
Stable Fast – Best Cost Performance by GPU
This measures the cost performance of Stable Fast across all image generation tasks for each GPU.
Observations
- Do not use the GTX series GPUs for production stable diffusion inference. Absolute performance and cost performance are dismal in the GTX series, and in many cases the benchmark could not be fully completed, with jobs repeatedly running out of CUDA memory. Additionally, many images generated on these GPUs came out all black, instead of as fancy QR codes as desired.
- There are very few surprises regarding which GPU is the fastest for each backend. Newer GPUs with higher model numbers are faster in nearly all situations.
- Batching saves time and money. In most situations, you can expect anywhere from 5-30% savings using batch size 4, vs batch size 1.
- Generation time scales close to linearly with number of pixels. a 768x768px image has 2.25x the pixels as a 512x512px image, and typically takes around 2x the time to generate.
- You can get surprisingly good cost performance out of the 20-series and 30-series RTX GPUs, regardless of the backend you choose.
- If you have a use-case that allows you to take advantage of the optimizations offered by Stable Fast, and the engineering availability to build and maintain an in-house solution, this is a great option that could save you a bunch of money while providing a fast and reliable image generation experience for your users.
- Many factors influence the scannability of these stable diffusion QR codes, and consistently getting good results is no simple task. Shorter URLs lead to better results, as there is less data to encode. Using QR codes with lighter backgrounds leads to easier scanning but less interesting images. Some prompts work much better than others, and some prompts can sustain much higher guidance than others. In addition, iOS and Android phones use different QR scanning implementations, so some codes scan fine on one platform but not the other.
Other Technology Choices
- R2 – S3-Compatible blob storage from Cloudflare with no bandwidth charges. We generated about 130GB of images, which has a monthly storage cost of $1.80. The write operations required fit within the free tier of usage. To handle secure uploads, we used pre-signed upload URLs included with each job.
- SQS – Fully managed message queue service from AWS. This whole benchmark fits within the free tier of usage.
- DynamoDB – Serverless NoSQL database from AWS. The entire benchmark fits within the free tier of usage.
- Lambda – Serverless functions from AWS. Used to provide HTTP endpoints constraining the use of SQS and DynamoDB. The entire benchmark fits within the free tier of usage.
Code and Docker Images
stable-fast– https://github.com/chengzeyi/stable-fast- Stable Fast QR Code Generator – https://github.com/SaladTechnologies/stable-fast-qr-demo
- Stable Fast QR Code Generator Docker Image: https://hub.docker.com/r/saladtechnologies/stable-fast-qr-code
- Automatic1111 – https://github.com/AUTOMATIC1111/stable-diffusion-webui
- Automatic1111 Dockerization: https://github.com/SaladTechnologies/stable-diffusion-webui-docker
- Automatic1111 Model Management: https://github.com/SaladTechnologies/a1111-dynamic
- Automatic1111 Docker Image: https://hub.docker.com/r/saladtechnologies/a1111
- SD.Next – https://github.com/vladmandic/automatic
- SD.Next Dockerization: https://github.com/shawnrushefsky/automatic/
- SD.Next Model Management: https://github.com/SaladTechnologies/sdnext-dynamic
- SD.Next Docker Image: https://hub.docker.com/r/saladtechnologies/sdnext
- ComfyUI – https://github.com/comfyanonymous/ComfyUI
- ComfyUI Dockerization: https://github.com/ai-dock/comfyui/
- ComfyUI Model Management: https://github.com/SaladTechnologies/comfyui-dynamic
- ComfyUI Docker Image: https://hub.docker.com/r/saladtechnologies/comfyui
- Benchmark Worker Process: https://github.com/SaladTechnologies/qr-code-worker
- Queue Management Lambda: https://github.com/SaladTechnologies/benchmark-queues
- Database Access Lambda: https://github.com/SaladTechnologies/benchmark-api



