
What is the Segment Anything Model (SAM)?
The Segment Anything Model (SAM) is a foundational image segmentation model released by Meta AI Research last year, with pre-trained model weights available through the GitHub repository. It can be prompted with a point or a bounding box, and performs well on a variety of segmentation tasks. More importantly, it carries the permissive Apache 2.0 license, allowing commercial use. As companies deploy this model for use cases ranging from image labeling, background removal, inpainting and more, cost of running SAM in production is a primary concern.
Benchmarking the Segment Anything Model (SAM) on SaladCloud
In this benchmark, we do an unprompted full-image segmentation on 152,848 images from the COCO 2017 and AVA image datasets. We evaluate inference speed and cost-performance across 302 nodes on SaladCloud representing 22 different consumer GPU classes. To do this, we created a container group targeting a capacity of 100 nodes, with the “Stable Diffusion Compatible” GPU class. All nodes were assigned 2 vCPU and 8GB RAM. Here’s what we found.
50K+ images segmented per dollar on RTX 3060 Ti & RTX 3070 Ti
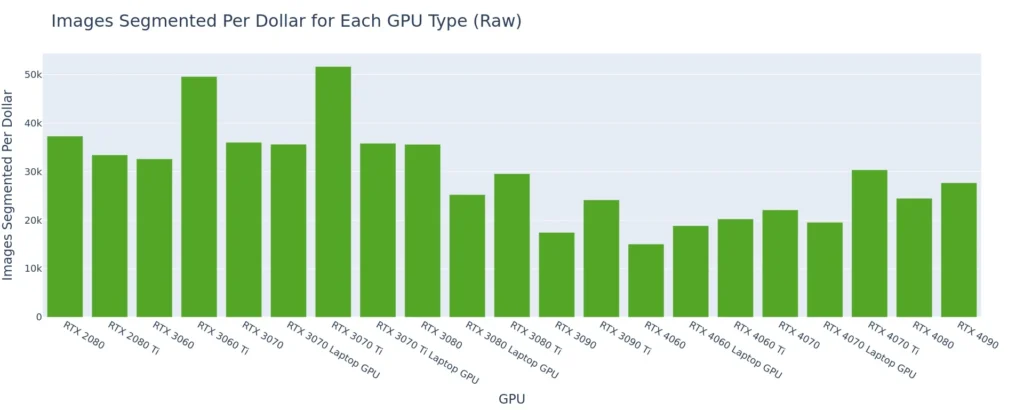
As is nearly always the case with smaller models, the best cost-performance is coming from the lower end GPUs, mostly the RTX 30-series cards. In this case, we see a significant bump in cost-performance on the Ti cards. This makes sense since they are priced the same as their non-Ti counterparts but have more CUDA cores. The stand-out performers here are the RTX 3060 Ti, and the RTX 3070 Ti, each offering at least 50k inferences per dollar.
Inference time is fairly consistent within a particular node
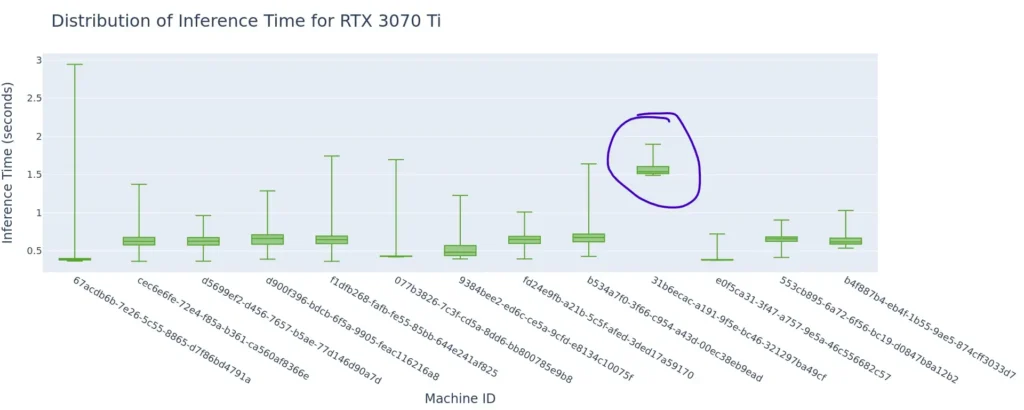
Zooming into performance within a single GPU class – the RTX 3070 Ti, we see that the bulk of inference times fall within a narrow range on any particular node, with some significant outliers. We do see some variability across different nodes, with one standing out as particularly bad. We often see a small amount of variability in performance across nodes on SaladCloud since each one is an individual residential gaming PC with a variety of different CPUs, RAM speeds, motherboard configurations, etc.
Our one outlier node (31b6, circled above) is indicative of something anomalous with that machine. We’re always working to get better at detecting these scenarios before your workloads get to a bad machine. But the best practice is to monitor the performance of your application, and terminate nodes that display anomalous behavior.
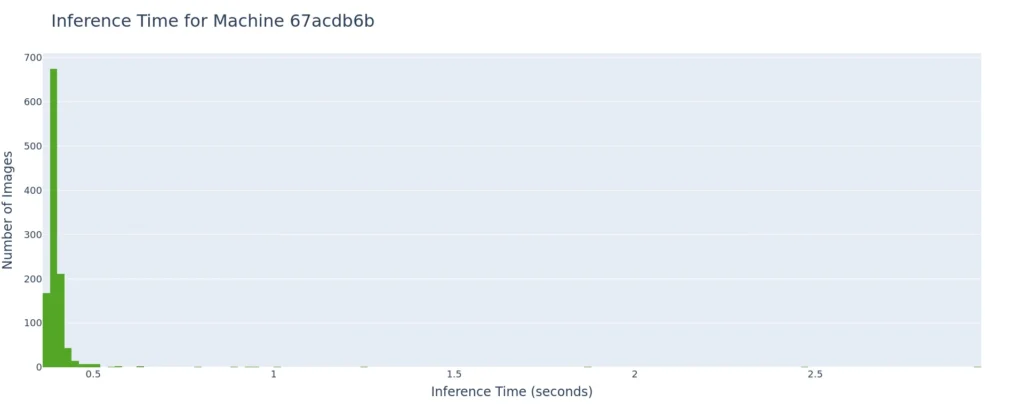
The range of inference time on one of our nodes (67acdb6b) may look concerning at first. But if we zoom in, we see those outlier times are exceedingly uncommon, with the vast majority of inferences clustered within a narrow range.
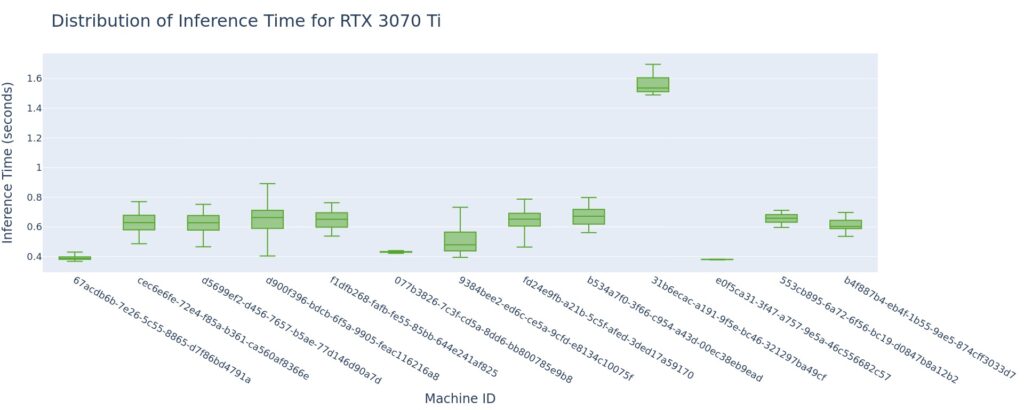
And indeed, if we filter out the outliers, we see a much tighter grouping within each individual node.
But we also start to see 2 distinct groupings of machines:
- Machines where inference times are around 400ms,
- Machines where inference times are around 650ms.
It is a little concerning that some machines are 35-40% faster than others, so this gets sent to our engineering team for further investigation. The above cost-performance numbers include all these outliers and variability, so I suspect that it is possible to beat those numbers.
Results from the Segment Anything Model (SAM) benchmark
The RTX 3060 Ti and RTX 3070 Ti running the Segment Anything Model (SAM) offer a highly cost-effective solution for batch image segmentation, coming in at 50x the cost efficiency of managed services like Azure AI Computer Vision.


