
What is the Recognize Anything Model++?
The Recognize Anything Model++ (RAM++) is a state of the art image tagging foundational model released last year, with pre-trained model weights available on huggingface hub. It significantly outperforms other open models like CLIP and BLIP in both the scope of recognized categories and accuracy. But how much does it cost to run RAM++ on consumer GPUs?
In this benchmark, we tag 144,485 images from the COCO 2017 and AVA image datasets, evaluating inference speed and cost performance. The evaluation was done across 167 nodes on SaladCloud representing 19 different consumer GPU classes. To do this, we created a container group targeting a capacity of 100 nodes with the “Stable Diffusion Compatible” GPU class. All nodes were assigned 2 vCPU and 8GB RAM. Here’s what we found.
Up to 309k images tagged per dollar on RTX 2080
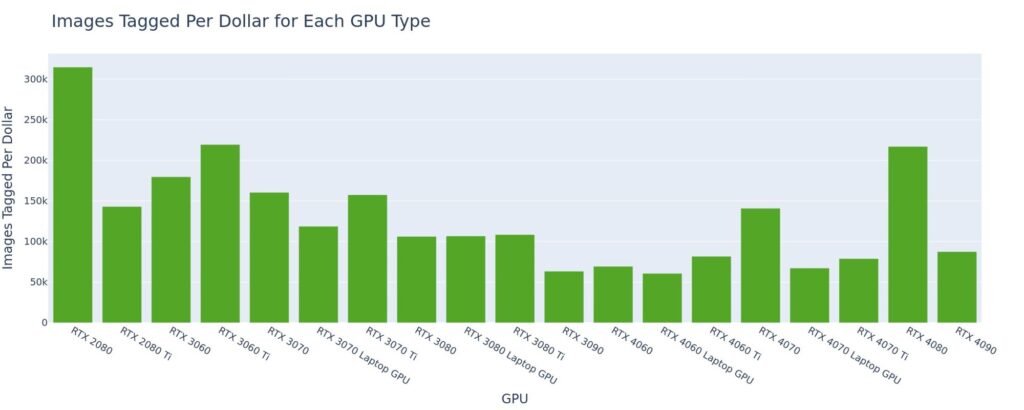
In keeping with a trend we often see here, the best cost-performance is coming from the lower end GPUs, RTX 20- and 30-series cards. In general, we find that the smallest/cheapest GPU that can do the job you need is likely to have the best cost-performance, in terms of inferences per dollar. RAM++ is a fairly small, lightweight model (3GB), and achieved its best performance on the RTX 2080, with just over 309k inferences per dollar.
Average Inference Time Is <300ms Across All GPUs
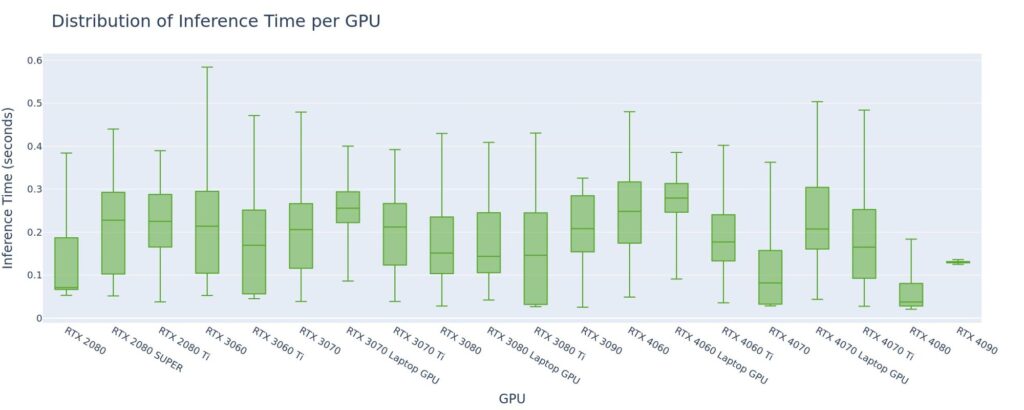
We see relatively quick inference times across all GPU types, but we also see a pretty wide distribution of performance, even within a single GPU type. Zooming in, we can see this wide distribution is also present within a single node.
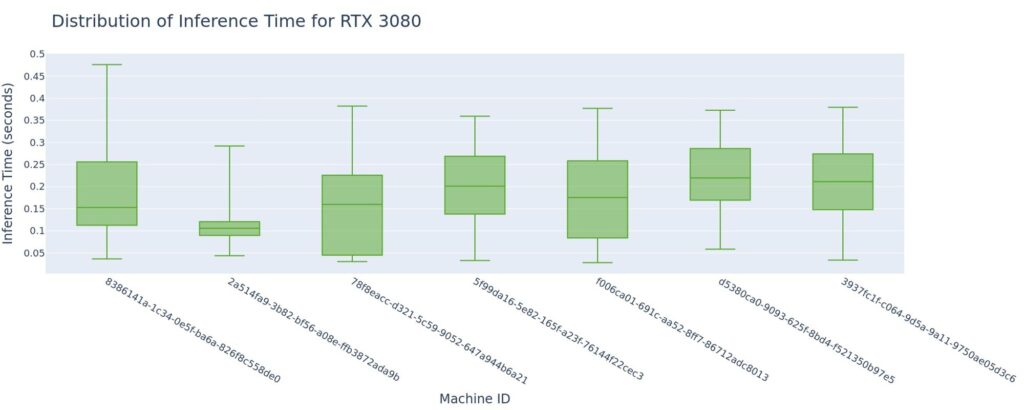
Further, we see no significant correlation between inference time and number of tags generated.
| GPU | Correlation between inference time and number of tags |
|---|---|
| RTX 2080 | 0.04255 |
| RTX 2080 SUPER | -0.02209 |
| RTX 2080 Ti | -0.03439 |
| RTX 3060 | 0.00074 |
| RTX 3060 Ti | 0.00455 |
| RTX 3070 | 0.00138 |
| RTX 3070 Laptop GPU | -0.00326 |
| RTX 3070 Ti | -0.01494 |
| RTX 3080 | -0.00041 |
| RTX 3080 Laptop GPU | -0.09197 |
| RTX 3080 Ti | 0.02748 |
| RTX 3090 | -0.00146 |
| RTX 4060 | 0.03447 |
| RTX 4060 Laptop GPU | -0.08151 |
| RTX 4060 Ti | 0.04153 |
| RTX 4070 | 0.01393 |
| RTX 4070 Laptop GPU | -0.05811 |
| RTX 4070 Ti | 0.00359 |
| RTX 4080 | 0.02090 |
| RTX 4090 | -0.03002 |
Based on this, you should expect to see a fairly wide variation in inference time in production regardless of your GPU selection or image properties.
Results from the Recognize Anything Model++ (RAM++) benchmark
Consumer GPUs offer a highly cost-effective solution for batch image tagging, coming in between 60x-300x the cost efficiency of managed services like Azure AI Computer Vision. The Recognize Anything paper and code repository offer guides to train and fine-tune this model on your own data, so even if you have unusual categories, you should consider RAM++ instead of commercially available managed services.


