
Parakeet TDT 1.1B GPU benchmark
The Automatic Speech Recognition (ASR) model, Parakeet TDT 1.1B, is the latest addition to NVIDIA’s Parakeet family. Parakeet TDT 1.1B boasts unparalleled accuracy and significantly faster performance compared to other models in the same family. Using our latest batch-processing framework, we conducted comprehensive tests with Parakeet TDT 1.1B against extensive datasets, including English CommonVoice and Spoken Wikipedia Corpus English(Part1, Part2).
In this detailed GPU benchmark, we will delve into the design and construction of a high-throughput, reliable, and cost-effective batch-processing system within SaladCloud. Additionally, we will conduct a comparative analysis of the inference performance between Parakeet TDT 1.1B and other popular ASR models like Whisper Large V3 and Distil-Whisper Large V2.
Advanced system architecture for batch jobs
Our latest batch-processing framework consists of the following:
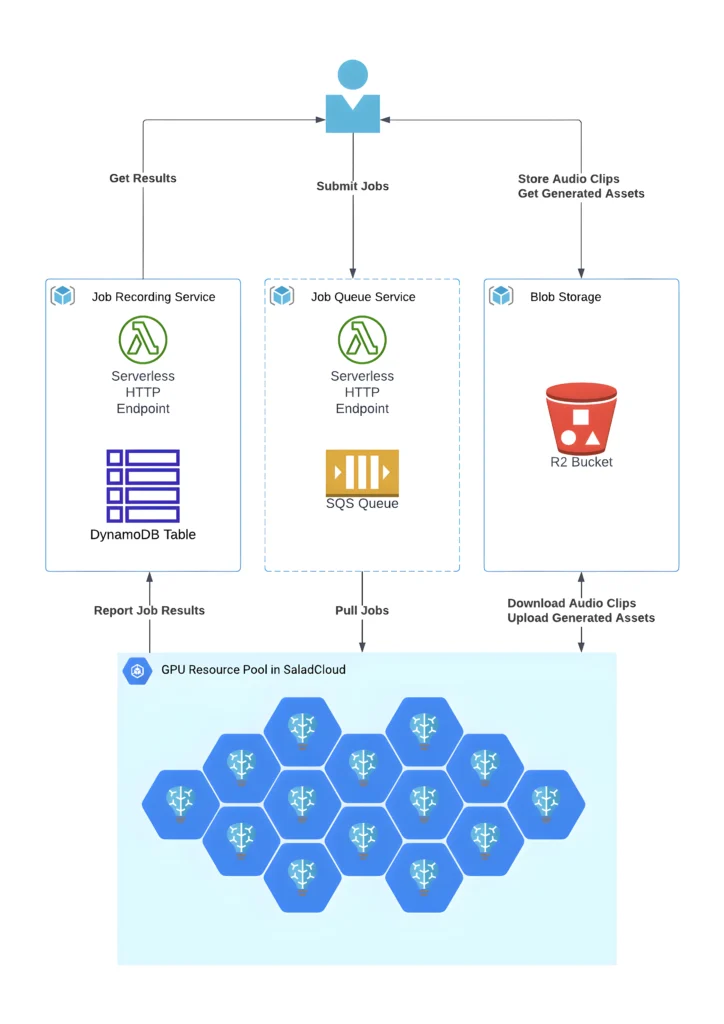
- GPU Resource Pool: Hundreds of Salad nodes equipped with dedicated GPUs are utilized for tasks such as downloading/uploading, pre-processing/post-processing, and transcribing.
- Cloud Storage: Audio files and generated assets are stored in Cloudflare R2, which is AWS S3-compatible and incurs zero egress fees.
- Job Queue System: The Salad nodes retrieve jobs via AWS SQS, providing unique identifiers and accessible URLs for audio clips in Cloudflare R2. Direct data access without a job queue is also possible based on specific business logic.
- Job Recording System: Job results, including input audio URLs, audio length, processing time, output text URLs, etc., are stored in NoSQL databases like AWS DynamoDB.
HTTP handlers using AWS Lambda or Azure Functions can be implemented for both the Job Queue System and the Job Recording System. This provides convenient access, eliminating the necessity of installing a specific Cloud Provider’s SDK/CLIs within the application container image.
We aimed to keep the framework components fully managed and serverless to closely simulate the experience of using managed transcription services. A decoupled architecture provides the flexibility to choose the best and most cost-effective solution for each component from the industry.
Enhanced Node Implementation for High Performance and Throughout
We have refined the node implementation to further enhance the system performance and throughput. Within each node in the GPU resource pool in SaladCloud, we follow best practices by utilizing two processes:
- One dedicated to GPU-based transcription inference and,
- Another focused on I/O- and CPU-bound tasks, such as downloading/uploading, pre-processing, and post-processing.
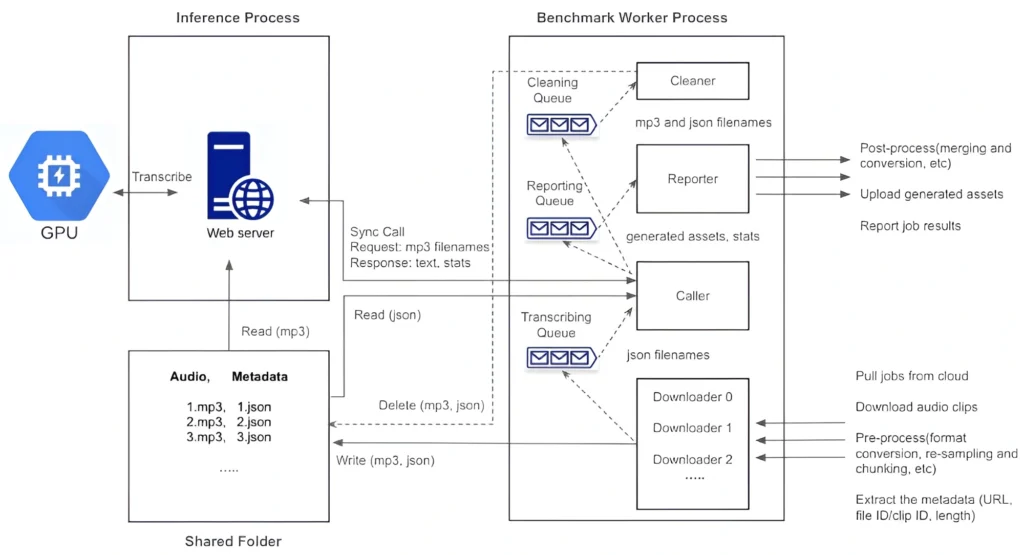
1) Inference Process
The transcription for audio involves resource-intensive operations on both CPU and GPU, including format conversion, re-sampling, segmentation, transcription and merging. The more CPU operations involved, the lower the GPU utilization experienced.
While having the capacity to fully leverage the CPU, multiprocessing or multithreading-based concurrent inference over a single GPU might limit optimal GPU cache utilization and impact performance. This is attributed to each inference running at its own layer or stage. The multiprocessing approach also consumes more VRAM as every process requires a CUDA context and loads its own model into GPU VRAM for inference.
Following best practices, we delegate more CPU-bound pre-processing and post-processing tasks to the benchmark worker process. This allows the inference process to concentrate on GPU operations and run on a single thread. The process begins by loading the model, warming up the GPU, and then listens on a TCP port by running a Python/FastAPI app on a Unicorn server. Upon receiving a request, it invokes the transcription inference and promptly returns the generated assets.
Batch inference can be employed to enhance performance by effectively leveraging GPU cache and parallel processing capabilities. However, it requires more VRAM and might delay the return of the result until every single sample in the input is processed. The choice of using batch inference and determining the optimal batch size depends on model, dataset, hardware characteristics and use case. This also requires experimentation and ongoing performance monitoring.
2) Benchmark Worker Process
The benchmark worker process primarily handles various I/O- and CPU-bound tasks, such as downloading/uploading, pre-processing, and post-processing.
The Global Interpreter Lock (GIL) in Python permits only one thread to execute Python code at a time within a process. While the GIL can impact the performance of multithreaded applications, certain operations remain unaffected, such as I/O operations and calling external programs.
To maximize performance with better scalability, we adopt multiple threads to concurrently handle various tasks, with several queues created to facilitate information exchange among these threads.
| Thread | Description |
|---|---|
| Downloader | In most cases, we require 2 to 3 threads to concurrently pull jobs and download audio files, and efficiently feed the inference pipeline while preventing the download of excessive audio files. The actual number depends on the characteristics of the application and dataset, as well as network performance. It also performs the following pre-processing steps: 1) Removal of bad audio files. 2) Format conversion and re-sampling. 3) Chunking very long audio into 15-minute clips. 4) Metadata extraction (URL, file/clid ID, length). The pre-processed audio files and their corresponding metadata JSON files are stored in a shared folder. Simultaneously, the filenames of the JSON files are added to the transcribing queue. |
| Caller | It reads a JSON filename from the transcribing queue, retrieves the metadata by reading the corresponding file in the shared folder, and subsequently sends a synchronous request, including the audio filename, to the inference server. Upon receiving the response, it forwards the generated texts along with statistics to the reporting queue, while simultaneously sending the transcribed audio and JSON filenames to the cleaning queue. The simplicity of the caller is crucial as it directly influences the inference performance. |
| Reporter | The reporter, upon reading the reporting queue, manages post-processing tasks, including merging results and format conversion. Eventually, it uploads the generated assets and reports the job results. Multiple threads may be required if the post-processing is resource-intensive. |
| Cleaner | After reading the cleaning queue, the cleaner deletes the processed audio files and their corresponding JSON files from the shared folder. |
By running two processes to segregate GPU-bound tasks from I/O and CPU-bound tasks, and fetching and preparing the next audio clips concurrently and in advance while the current one is still being transcribed, eliminates any waiting period.
After one audio clip is completed, the next is immediately ready for transcription. This approach not only reduces the overall processing time for batch jobs but also leads to even more significant cost savings.
Single-Node Test using JupyterLab on SaladCloud
Before deploying the application container image on a large scale in SaladCloud, we can build a specialized application image with JupyterLab and conduct the single-node test across various types of Salad nodes.
With JupyterLab’s terminal, we can log into a container instance running on SaladCloud and gain OS-level access. This enables us to conduct various tests and optimize the configurations and parameters of the model and application. These include:
- Measuring the time to download the model and then load it into the GPU, including warm-up, to define the appropriate health check count.
- Analyzing the VRAM usage variations during the inference process based on long audio lengths and different batch sizes and selecting the best performing or most cost-effective GPU types for the application.
- Determining the minimum number of downloader threads required to efficiently feed the inference pipeline.
- Identifying and handling various possible exceptions during application runtime, etc.
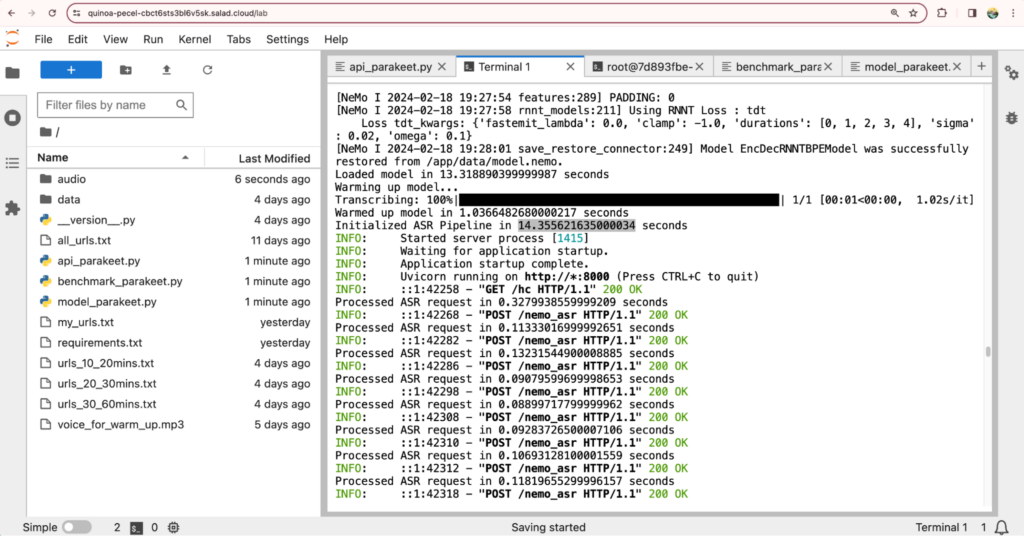
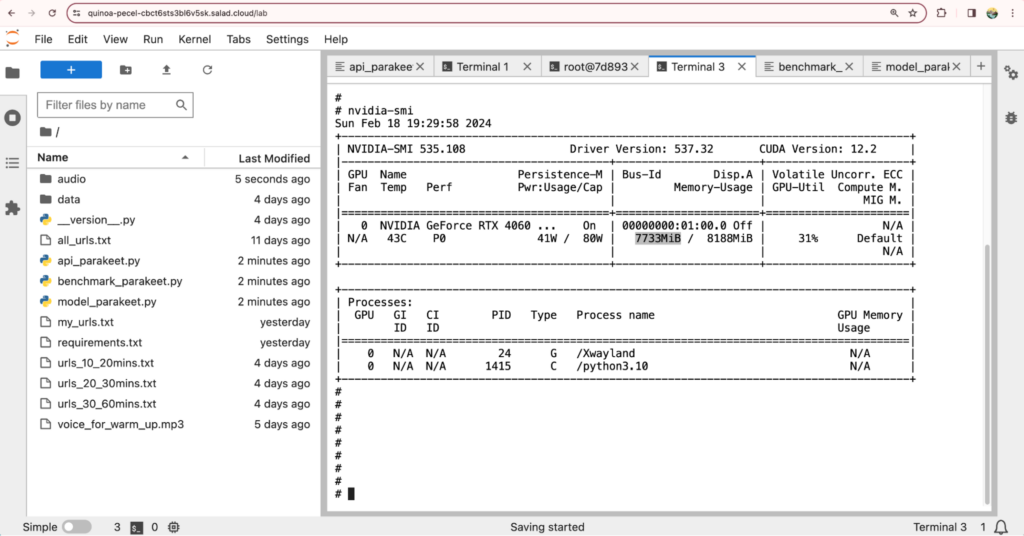
Analysis of single-node test using JupyterLab
Based on our tests using JupyterLab, we found that the inference of Parakeet TDT 1.1B for audio files lasting longer than 15 minutes (or its batch inference for 15 1-minute audio files) requires approximately 7GB VRAM, excluding the process CUDA context. To optimize utilization and leverage massive and more cost-effective GPU types with 8GB of VRAM, we have decided to segment all long audio into 15-minute clips using the downloader threads.
Given the high-speed performance of Parakeet TDT 1.1B and the presence of numerous small audio files in our datasets (averaging 12 seconds per audio), resulting in low network transmission efficiency, we have opted to use a minimum of 3 download threads for downloading and pre-processing audio files, based on our tests.
Considering occasional downtimes from the Hugging Face website and the possibility of container instances being rebooted, we have pre-built the container image with the model, adding approximately 4GB to its size. This strategy eliminates dynamic downloads during the application’s runtime, contributing to cost reduction.
The above analysis underscores the importance of conducting a single-node test for constructing a high-throughput, performance-optimized system with an eye on cost-efficiency.
For more information on running JupyterLab over SaladCloud, please refer to the user guide.
Massive Transcription Tests for Parakeet TDT 1.1B on SaladCloud
We created a container group with 100 replicas (2vCPU and 12 GB RAM with 20+ different GPU types) in SaladCloud. The group was operational for approximately 10 hours, from 10:00 pm to 8:00 am PST. We successfully transcribed a total of 5.2 million audio files. The cumulative length of these audio files amounted to 17,305 hours, with an average duration of 12 seconds.
The results are different from those obtained in local tests with several machines in a LAN. These numbers are achieved in a global and distributed cloud environment that provides the transcription at a large scale. This includes the entire process from receiving requests to transcribing and sending the responses.
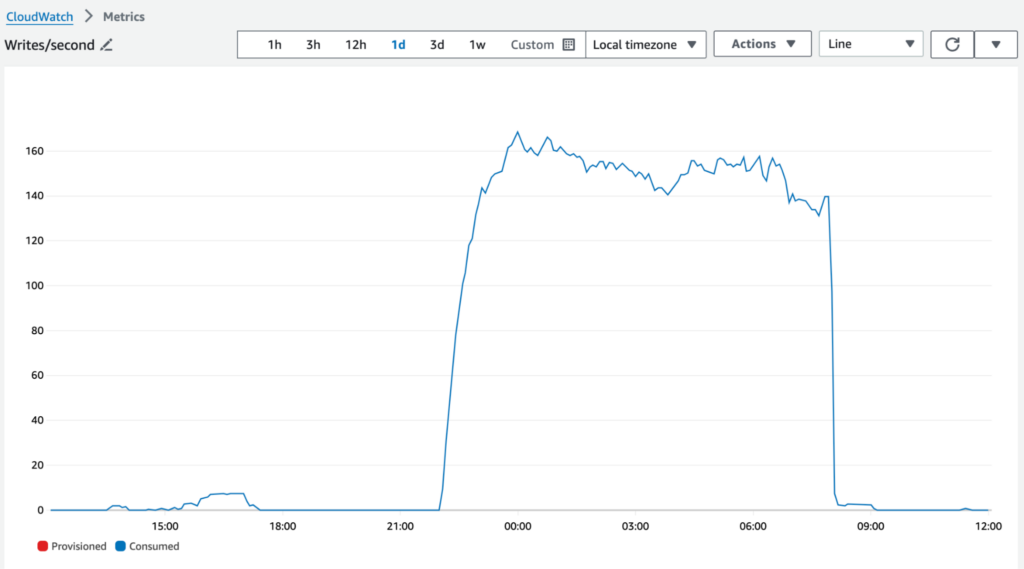
According to the AWS DynamoDB metrics, specifically writes per second, which serve as a monitoring tool for transcription jobs, it’s evident that the system reached its maximum capacity, processing approximately 150 audio files per second, roughly one hour after the container group was created. This observation underscores the importance of pre-warming the applications deployed on SaladCloud to effectively handle peak traffic.
Inference performance comparison of Parakeet TDT 1.1B, Whisper Large V3 and Distil-Whisper Large V2
| Whisper Large V3 | Distil-Whisper Large V2 | Parakeet TDT 1.1B | |
|---|---|---|---|
| Cost on SaladCloud (GPU Resource Pool) | Around $100 100 Replicas (2vCPU,12GB RAM,20+ GPU types) for 10 hours | Around $100 100 Replicas (2vCPU,12GB RAM,20+ GPU types) for 10 hours | Around $100 100 Replicas (2vCPU,12GB RAM,20+ GPU types) for 10 hours |
| Cost on AWS and Cloudflare (Job Queue/Recording System and Cloud Storage ) | Less than $10 | Around $15 | Around $20 |
| Node Implementation | 2 processes; 1 downloader thread in the benchmark work process. | 2 processes; 1 downloader thread in the benchmark work process. | 2 processes; 3 downloader threads and segmentation of long audio (15 mins) in the benchmark work process. |
| Number of Transcribed Audio Files | 2,364,838 | 3,846,559 | 5,209,130 |
| Total Audio Length (s) | 28,554,156 (8000 hours) | 47,207,294 (13113 hours) | 62,299,198 (17305 hours) |
| Average Audio Length (s) | 12 | 12 | 12 |
| Most Cost-Effective GPU Type for transcribing long audio files exceeding 30 seconds | RTX 3060 196 hours per $ | RTX 2080 Ti 500 hours per $ | RTX 3070 Ti 794 hours per $ |
| Most Cost-Effective GPU Type for transcribing short audio files lasting less than 30 seconds | RTX 2080/3060/3060 Ti/3070 Ti 47 hours per $ | RTX 2080/3060 Ti 90 hours per $ | RTX 2080 Ti 228 hours per $ |
| Best-Performing GPU Type for transcribing long audio files exceeding 30 seconds | RTX 4080 Average real-time factor: 40, transcribing 40 seconds of audio per second | RTX 4090 Average real-time factor: 93, transcribing 93 seconds of audio per second | RTX 3080Ti Average real-time factor: 131, transcribing 131 seconds of audio per second |
| Best-Performing GPU Type for transcribing short audio files lasting less than 30 seconds | RTX 3080 Ti/4070 Ti/4090 Average real-time factor: 8, transcribing 8 seconds of audio per second | RTX 4090 Average real-time factor: 14, transcribing 14 seconds of audio per second | RTX 4070 Average real-time factor: 35, transcribing 35 seconds of audio per second |
| System Throughput | Transcribing 793 seconds of audio (66 inferences) per second | Transcribing 1311 seconds of audio (107 inferences) per second | Transcribing 1731 seconds of audio (145 inferences) per second. |
Analysis of inference comparison for the three speech-to-text models
Evidently, Parakeet TDT 1.1B outperforms both Distill-Whisper Large V2 and Whisper Large V3 in both performance and cost-effectiveness, especially for short audio duration. Unlike conventional ASR models, which produce a lot of blanks during inference, Parakeet TDT (Token-and-Duration Transducer) can skip the majority of blank predictions, thus bringing significant inference speed-up by reducing wasteful computations and lowering cost while maintaining the same recognition accuracy.
By introducing multiple threads to download audio files concurrently, we offload more CPU-bound preprocessing and post-processing tasks, such as chunking and merging, to the benchmark worker process. This allows the inference process to focus on the GPU operations and run over massive and more cost-effective GPUs types. We can now fully unleash the potential of the model, resulting in increased system throughput and reduced costs.
There are various methods to further optimize the results, aiming for reduced costs, improved performance or even both. Different approaches may yield distinct outcomes.
In a global and distributed cloud environment offering services at a large scale, various factors can impact overall performance. These include distance, transmission and processing delays, model size, and performance, among others. Hence, a comprehensive approach is essential for system design and implementation. This approach should encompass use cases, business goals, resource configuration, and algorithms, among other considerations.
Performance comparison across different clouds
With the high-speed ASR model – Parakeet TDT 1.1B, and the advanced batch-processing framework leveraging hundreds of consumer GPUs in SaladCloud and enhanced node implementation, we can deliver transcription services at a massive scale and at an extremely low cost while maintaining the same level of accuracy as managed transcription services.
With the most cost-effective GPU type for the inference of Parakeet TDT 1.1B in SaladCloud, $1 dollar can transcribe 47,638 minutes of audio (nearly 800 hours). This is over a 1000-fold cost reduction compared to other public cloud providers. We believe this approach will fundamentally transform the speech recognition industry’s push for more profitability.
SaladCloud: The most affordable GPU cloud for batch jobs
Consumer GPUs are considerably more cost-effective than data center GPUs. While they may not be the ideal choice for extensive and large model training tasks, they are powerful enough for the inference of most AI models. With the right design and implementation, we can build a high-throughput, reliable and cost-effective system on top of them, offering massive inference services.
If your requirement involves hundreds of GPUs for large-scale inference or handling batch jobs, or you need tens of different GPU types within minutes for testing or research purposes, SaladCloud is the ideal platform.
SaladCloud is the world’s largest distributed cloud computing network with 11,000+ daily GPUs and 450,000 GPUs contributing compute, all at the lowest cost in the market.


