
What is OpenVoice?
OpenVoice is an open-source, instant voice cloning technology that enables the creation of realistic and customizable speech from just a short audio clip of a reference speaker. Developed by MyShell.ai, OpenVoice stands out for its ability to precisely replicate the voice’s tone color while offering extensive control over various speech attributes such as emotion and rhythm.
Remarkably, it also supports zero-shot cross-lingual voice cloning, enabling the generation of speech in languages not originally included in its extensive training set. OpenVoice is not only versatile but also exceptionally efficient, requiring significantly lower computational resources compared to commercially available text-to-speech (TTS) APIs, often at a fraction of the cost and with superior performance.
For developers and organizations interested in exploring or integrating OpenVoice, the technical report and source code are available at arXiv and GitHub.
The OpenVoice framework: An overview
The OpenVoice technology encompasses a sophisticated framework designed to replicate human speech with remarkable accuracy and versatility. The process involves several key steps, each contributing to the creation of natural-sounding and personalized voice output. Here’s a closer look at the OpenVoice framework:
- Text-to-Speech (TTS) Synthesis: At the core of the OpenVoice framework is its TTS engine, which converts written text into spoken words. This initial step utilizes a base speaker model to
generate speech that serves as the foundation for further customization. - Tone Extraction: Following the TTS synthesis, OpenVoice extracts the tone characteristics from a reference voice sample.
- Tone Color Embodiment: The final step involves integrating the extracted tone color into the speech generated by the TTS engine. You can also ensure that the output not only replicates the
voice tone of the reference speaker but also add distinctive vocal signature such as rhythm and intonation.
Here is an illustration from the official technical report.
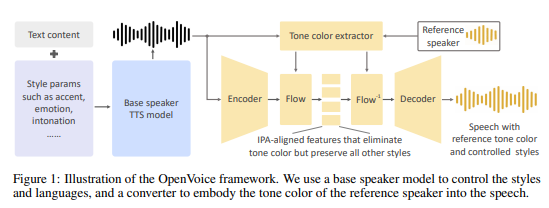
Methodology of the OpenVoice Text-to-Speech (TTS) benchmark on SaladCloud GPUs
For this initial benchmark, we have focused exclusively on the Text-to-Speech (TTS) component of OpenVoice, setting the stage for a more comprehensive analysis that will include full TTS and voice cloning in a future benchmark. Utilizing the default voice parameters with a speed setting of 1, our base text was the book “Robots and Empire” by Isaac Asimov, available via Archive.org, totaling approximately 150,000 words.
To manage memory efficiency and ensure seamless processing, we broke down and processed the text into chunks of roughly 30 sentences, or 200-300 words.
Our evaluation spanned all consumer GPU classes available on SaladCloud, with each node provisioned with 1 vCPU and 8GB of RAM. To simulate a single-task environment typical of many production systems, we did not employ threading. Thus, each GPU was tasked with processing one chunk of text at a time. This setup provides insight into the raw processing power of each GPU class without the performance enhancements of parallel processing.
The workflow involved downloading the text from Azure, processing it through the TTS component of OpenVoice, and then uploading the resulting audio back to Azure. This end-to-end process allowed us to assess not only the computational performance of each GPU but also the impact of network bandwidth and data transfer efficiencies.
Benchmark findings: Cost-performance and inference speed
Words per dollar efficiency
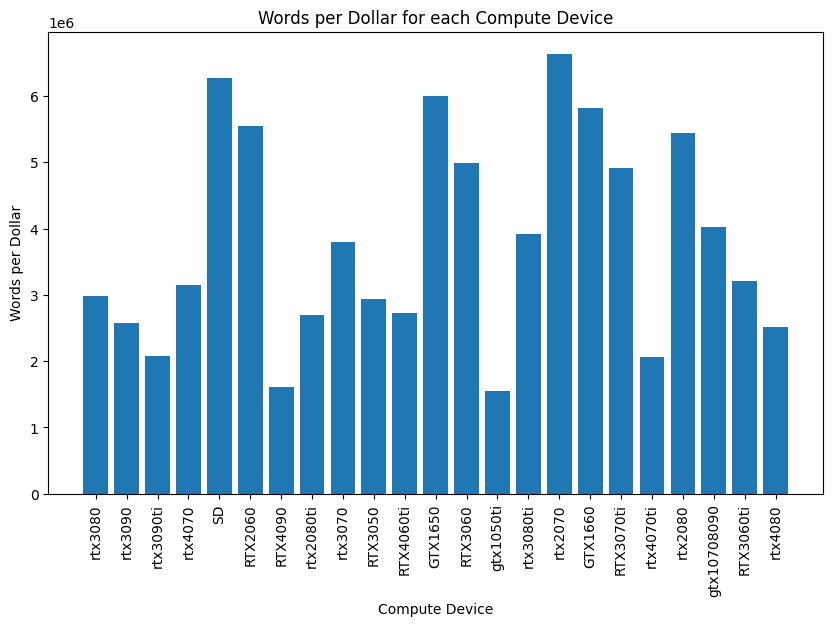
For our first analysis, we only tracked GPU processing time without considering text download and audio upload time. The first plot revealed a clear leader in terms of cost-efficiency: the RTX 2070 GPU, which processed an impressive 6.6 million words per dollar, excluding the time for text download and audio upload. This metric is crucial for organizations that need to optimize their operating costs without compromising on output volume. The price of using RTX2070 on SaladCloud is $0.06/hour, which, together with the vCPU and RAM we used, got us to a total of $0.072/hour.
Average words per second
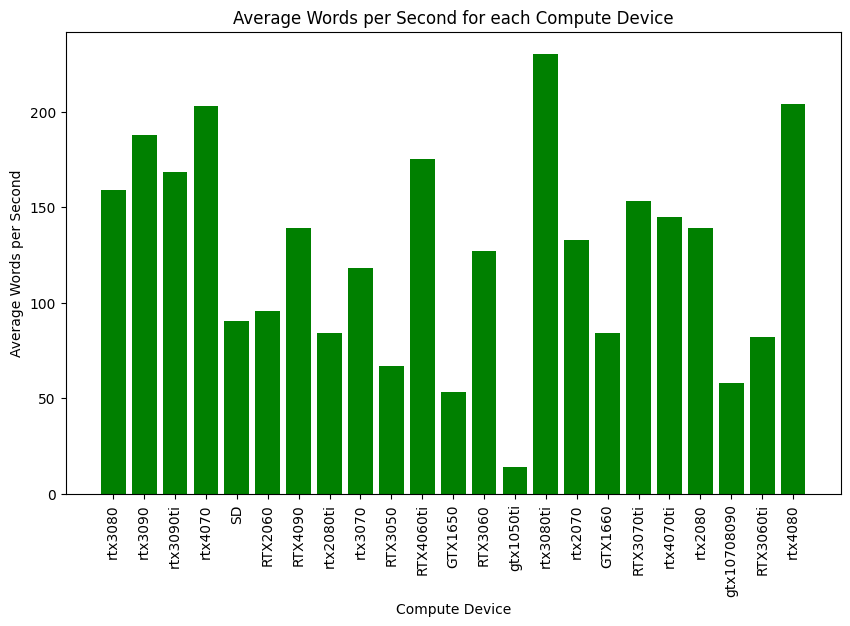
In terms of raw speed, the second plot shows that the RTX 3080 Ti topped the charts, achieving around 230.4 words per second. While the RTX 2070 lagged behind at approximately 132.7 words per second, its lower operational cost of $0.06 per hour compared to the RTX 3080 Ti’s $0.20 per hour makes it an attractive option for cost-conscious deployments. If you are interested in processing your text faster, RTX3080+ will be the best choice.
Words per dollar, including data transfer times
The third plot introduced the reality of data transfer times, showcasing how the words-per-dollar metric shifts when including the time to download and upload data to and from Azure. In this scenario, the RTX 2070 remained efficient, processing 4.53 million words per dollar. This efficiency hints at further potential savings if data transfers are optimized, such as by processing data in parallel with downloads/uploads, which we did not include in our process.
The Potential of Multithreading
While this benchmark focused on single-threaded operations, it’s worth noting that the capacity for multithreading on more powerful GPUs like the RTX 3080 Ti could narrow the cost-performance gap. By processing multiple text chunks simultaneously, these GPUs could deliver even more words per dollar, adding a layer of strategic decision-making for organizations balancing speed and cost.
Conclusion: Insights for TTS Deployment and Azure Comparison
Through our benchmarking of the OpenVoice TTS component on SaladCloud GPUs, we have identified the following:
- The RTX 2070 is the most cost-effective option for mass text-to-speech processing
- The RTX 3080 Ti offered the highest processing speed
To put these findings in perspective, let’s compare them with the pricing structure of Azure’s Speech Services. Azure Speech Services offers various tiers and features in its pricing model.
For standard text-to-speech (TTS) services, the price is $1 per hour for real-time processing and $0.36 per hour for batch processing.
This pricing can increase with custom models and endpoint hosting, reaching up to $1.20 per hour plus additional costs for model hosting. There is also a per character pricing option in Azure which is $15 per 1 million characters for real-time and batch synthesis.
In contrast, our benchmark with OpenVoice on SaladCloud GPUs has demonstrated that the RTX 2070 can process an impressive 6.6 million words per dollar, excluding network transfer times. Even when including the time for text download and audio upload, the RTX 2070 achieves 4.53 million words per dollar.
Given that the average English word is around 5 characters long, this means that, for the cost of processing 1 million characters on Azure, you could potentially process up to 300+ million characters using OpenVoice on SaladCloud GPUs.
Therefore, when considering factors such as budget constraints and processing speed requirements, OpenVoice on SaladCloud GPUs emerges as a compelling alternative to managed services like Azure Speech Services. It offers not just a cost advantage but also the potential for greater customization and scalability – a powerful combination for businesses and developers looking to integrate advanced voice synthesis capabilities into their applications.


