
Deploy your own LLM with Ollama & Huggingface Chat UI on SaladCloud
How much does it cost to build and deploy a ChatGPT-like product today? The cost could be anywhere from thousands to millions – depending on the model, infrastructure, and use case. Even the same task could cost anywhere from $1000 to $100,000. But with the advancement of open-source models & open infrastructure, there’s been tremendous interest in building a cost-efficient ChatGPT-like tool for various real-life applications. In this article, we explore how tools like Ollama and Huggingface Chat UI can simplify this process, particularly when deployed on Salad’s distributed cloud infrastructure.
The challenges in hosting & implementing LLMs
In today’s digital ecosystem, Large Language Models (LLMs) have revolutionized various sectors, including technology, healthcare, education, and customer service. Their ability to understand and generate human-like text has made them immensely popular, driving innovations in chatbots, content creation, and more. These models, with their vast knowledge bases and sophisticated algorithms, can converse, comprehend complex topics, write code, and even compose poetry. This makes them highly versatile tools for many enterprise & everyday use cases.
However, hosting and implementing these LLMs poses significant challenges.
- Sourcing computational power is required since these models can often have billions of parameters and demand robust infrastructure.
- Managing costs while ensuring performance since the choice between API calls, managed LLMs and custom LLMs on a cloud can change cost significantly.
- Integrating LLMs into existing systems requires a deep understanding of machine learning, natural language processing, and software engineering.
- Ensuring privacy, ethics, accuracy & relevance with robust data privacy, ethical handling of user inputs, maintaining model accuracy/relevance with ongoing training.
Despite these challenges, the integration of LLMs into platforms continues to grow, driven by their vast potential and the continuous advancements in the field. As solutions like Hugging Face’s Chat UI
and SaladCloud continue to offer more accessible and efficient ways to deploy these models, we’re likely to see an even greater adoption and innovation across industries.
What is Ollama?
Ollama is a tool that enables the local execution of open-source large language models like Llama 2 and Mistral 7B on various operating systems, including Mac OS, Linux, and soon Windows. It simplifies the process of running LLMs by allowing users to execute models with a simple terminal command or an API call.
Ollama optimizes setup and configuration, specifically tailoring GPU usage for efficient performance. It supports a variety of models and variants, all accessible through the Ollama model library, making it a versatile and user-friendly solution for running powerful language models locally.
Here is a list of supported models:
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama2 | 7B | 3.8GB | ollama run llama2 |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Dolphin Phi | 2.7B | 1.6GB | ollama run dolphin-phi |
| Phi-2 | 2.7B | 1.7GB | ollama run phi |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini |
| Vicuna | 7B | 3.8GB | ollama run vicuna |
| LLaVA | 7B | 4.5GB | ollama run llava |
What is Huggingface Chat UI?
Huggingface Chat UI is a powerful tool for practitioners in the Large Language Model (LLM) space looking to deploy a ChatGPT-like conversational interface. It enables interaction with models hosted
on Huggingface, leveraging its text generation inference or any custom API powered by LLM. Chat UI has such capabilities as conversational history, memory, authentication, and theming.
Huggingface Chat UI is an ideal choice for those looking to create a more engaging and robust conversational agent.
Integrating Ollama and Huggingface Chat UI for deploying on SaladCloud
The main goal of our project is to integrate Ollama with Huggingface Chat UI and deploy them to SaladCloud.
The final version of the code can be found here: GitHub – SaladTechnologies/ollama-chatui
In order to achieve our goal, we did the following:
1. Clone Ollama Repository
We start by cloning the Ollama repository from Ollama Git Repo. This repository serves as the base of the project.
Ollama is a user-friendly tool and can be operated via terminal or as a REST API. In this project, the intention is to run Ollama in a Docker container and connect it to Chat UI. The Dockerfile from Ollama repository shows that it runs on host 0.0.0.0 and port 11434. However, since direct access to Ollama isn’t required but rather through the UI, this configuration will be modified later.
2. Setting Up Huggingface Chat UI
Chat UI git repo: GitHub – huggingface/chat-ui: Open source codebase powering the HuggingChat app
From the Chat UI Readme, we can see that we need to follow a few steps to make it work in our custom solution:
- .env.local File: We need to create a
.env.localfile with model settings specific to our needs. This will include environmental variables that the Chat UI will use to function properly. - MongoDB URL: The Chat UI requires a database to store chat history. A local MongoDB instance can be used, but we will use a free MongoDB Atlas instance. Chat UI fits comfortably within the free tier, giving an opportunity to share the chat history between different deployments. The
MONGODB_URLwith the link to our MongoDB instance has to be added to.env.local file. - Hugging Face Token: Some models may require authentication to download or interact with. As such, a Hugging Face token (
HF_TOKEN) is necessary. This token should also be added to the.env.local file. - Model Configuration: Huggingface Chat UI supports the Ollama inference server. Spin up the server with the model first. The model configuration has to be added to the .env.local file as well. The full file will look something like this:
MONGODB_URL=<the URL to your MongoDB instance>
HF_TOKEN=<your access token>
MODELS=`[
{
"name": "Ollama Mistral",
"chatPromptTemplate": "<s>{{#each messages}}{{#ifUser}}[INST] {{#if @first}}{{#if @root.preprompt}}{{@root.preprompt}}\n{{/if}}{{/if}} {{content}} [/I
"parameters": {
"temperature": 0.1,
"top_p": 0.95,
"repetition_penalty": 1.2,
"top_k": 50,
"truncate": 3072,
"max_new_tokens": 1024,
"stop": ["</s>"]
},
"endpoints": [
{
"type": "ollama",
"url" : "http://127.0.0.1:11434",
"ollamaName" : "mistral"
}
]
}
]`Notice that the path to ollama is specified as http://127.0.0.1:11434.
3. Connecting Ollama and Chat UI
We now need to connect Ollama and ChatUI. This involves ensuring that the Chat UI can communicate with the Ollama instance, typically by setting the appropriate port and host settings in the UI configuration to match the Ollama Docker deployment.
First we clone the ChatUI repo in our Dockerfile and replace the host that Ollama uses with 127.0.0.1. Next expose port 3000 that is used by ChatUi.
We will also replace the entry point with our custom shell script:
#!/bin/bash
touch .env.local
echo "MONGODB_URL=${MONGODB_URL}" > .env.local
echo "HF_TOKEN=${HF_TOKEN}" >> .env.local
cat models_config/model.local >> .env.local
sed -i "s/model_placeholder/${MODEL}/g" .env.local
tmux new-session -d -s ollama "ollama run ${MODEL}"
echo "sleep for ${DOWNLOAD_TIME} minutes"
sleep ${DOWNLOAD_TIME}
npm install unplugin-icons
npm run dev -- --host :: --port 3000With this script, we establish the necessary .env.local file and populate it with configurations. Next, we initiate the Ollama server in a separate tmux session to download the desired model. ChatUI is then activated on port 3000.
For any adjustments in model settings, refer to the models_config/model.local file. We have also converted the MongoDB URL, Huggingface Token, and Model name into environment variables to facilitate seamless alterations during deployment to SaladCloud.
Additionally, a DOWNLOAD_TIME variable is defined. Since Ollama runs in a tmux session, subsequent commands can be executed even if the server isn’t fully operational. To ensure that Ollama is fully active before initiating ChatUI, we incorporate a sleep duration. This duration is model-dependent for
instance, downloading llama2 might take around 8 minutes.
4. Deploying to SaladCloud
After setting up and connecting Ollama and Chat UI, the complete system is ready for deployment to Salad’s cloud infrastructure. The integrated solution will be hosted on Salad’s robust cloud platform.
Detailed deployment instructions and necessary files are accessible through the Salad Technologies Ollama Chat UI GitHub repository or by pulling the image from the Salad Docker Registry: saladtechnologies/ollama-chatui-salad:1.0.0.
To deploy our solution, we need to follow the instructions: Deploy a Container Group with SaladCloud Portal.
Most deployment settings are basic, but there are also some specifics:
- Pick the image: If you do not want to make any custom changes, specify the docker image provided by Salad as the image source.
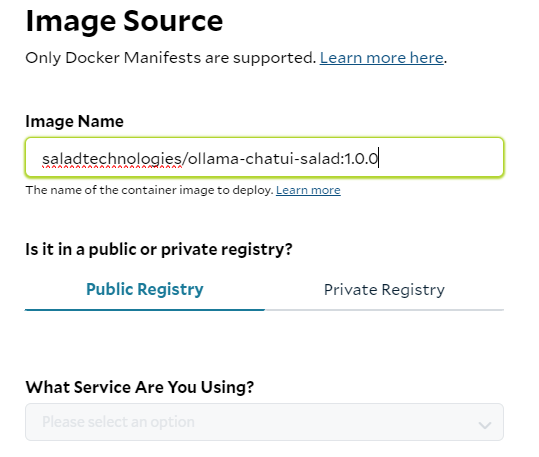
2. Configure Networking: Specify the correct port for accessing your UI under the networking settings. For this setup, port 3000 is used. Consider adding authentication features to enhance the security of your connection.
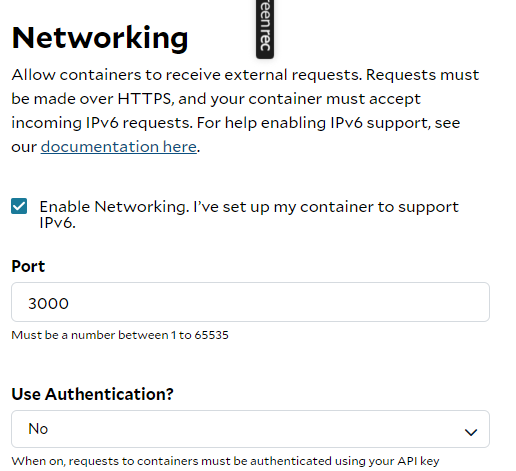
3. Set Environment Variables: Provide all required environment variables for the deployment. For this instance, you need to set:
MONGODB_URL:The link to your MongoDB instance.HF_TOKEN:Your Hugging Face access token.MODEL:The model you plan to use, which in this case is llama2.DOWNLOAD_TIME:Given llama2 is 3.8GB, a 10-minute download time should suffice.
4. Initiate Deployment: Once everything is configured, click “Deploy“. This will start the process of downloading the image and deploying it to the SaladCloud cluster. This process typically takes about 5
10 minutes.
5. Post-Deployment Wait: Remember that after the deployment, there’s an additional wait time of around 10 minutes to allow the Ollama server to download the model.
6. Access and Verification: After the wait time, you can access your deployment URL to check the results and verify that everything is functioning as intended.
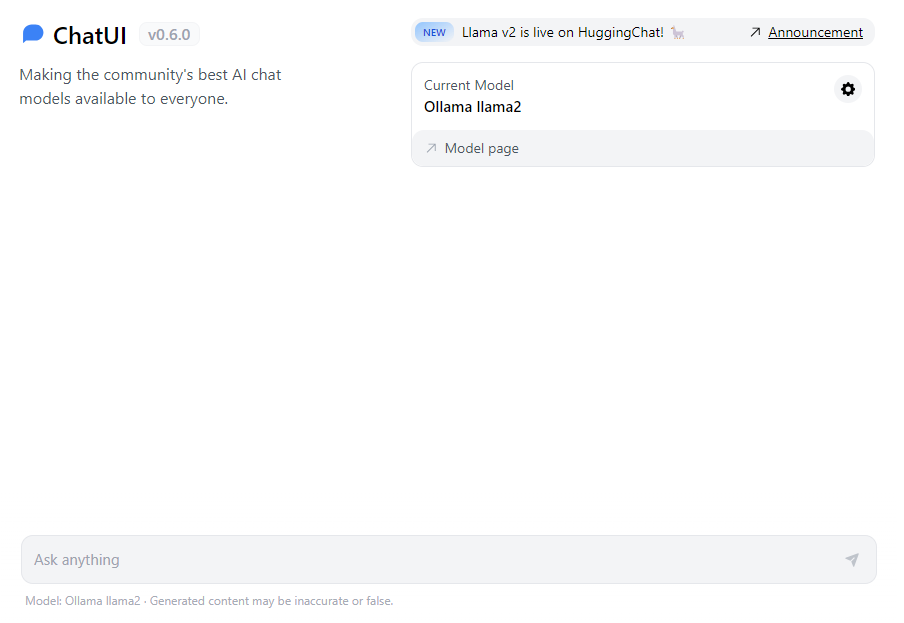
We can see our ChatUI is up and running.
Compute Performance difference
When evaluating the performance differences across various compute configurations, it’s essential to look at both the cost and the speed of response. We ran the Ollama and Chat UI solution with the Llama2 model on different computes, asking the same question: “What are the best New Year’s Recipes?“
1. High-End GPU (RTX 3090)
- Configuration: 8vCPUs, 8 GB RAM, RTX 3090
- Cost: $0.29 per hour
- Performance: The response was impressively fast, loading in less than a second and delivering 15 New Year’s recipes in less than 10 seconds.
2. CPU Only
- Configuration: 8vCPUs, 8 GB RAM
- Cost: $0.04 per hour
- Performance: While the quality of the response remained high, the absence of a GPU significantly affected the speed. It took approximately 4 minutes and 30 seconds for the model to process the
request and generate a response.
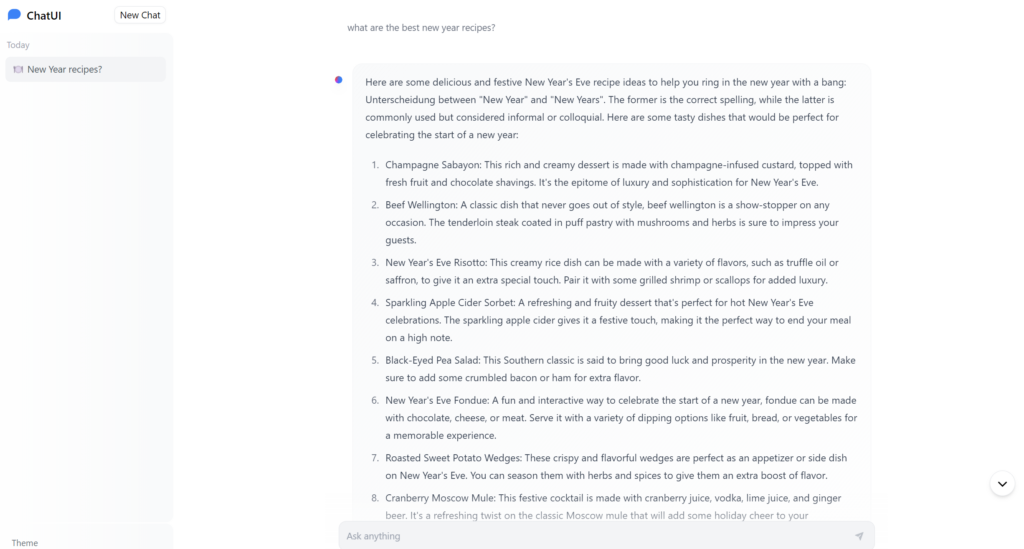
3. Budget GPU (RTX 3060):
- Configuration: 8vCPUs, 8 GB RAM, RTX 3060
- Cost: $0.12 per hour
- Performance: The RTX 3060 took slightly longer (2-3 seconds) to load the request compared to the RTX 3090. However, once loaded, the response time was nearly as quick as the more
expensive GPU.
The experiment highlights the trade-offs between cost and performance when choosing compute resources for deploying LLMs like Llama2. The high-end GPU (RTX 3090) offered the fastest response but at a higher cost. On the other hand, the CPU-only option significantly reduced costs but at the expense of response time, making it suitable for non-time-sensitive tasks.
The budget GPU (RTX 3060) represents a middle ground, providing a balance between cost and performance, with only a slight increase in response time compared to the high-end option. Therefore, the choice of compute should be guided by the specific needs and constraints of the application, considering both the budget and the required speed of response.
Deploying a ChatGPT-like tool with Ollama & Huggingface Chat for just $0.04 per hour
In conclusion, through this article, we have explored the integration of Ollama with Huggingface Chat UI, focusing on deploying this combination to Salad’s cloud infrastructure and evaluating its performance across different computing environments. Our process involved simplifying the execution of large language models like Llama 2 with Ollama, while enhancing user experience with the feature-rich Huggingface Chat UI.
The performance tests across various hardware configurations, from high-end GPUs to CPUs, highlighted the trade-offs between cost and processing speed. Our goal is to demonstrate conversational AI’s growing accessibility. By deploying on SaladCloud, we achieved widespread hosting availability and improved efficiency, enabling us to deploy our own LLM with a UI starting at only $0.04 per hour.
SaladCloud is the world’s largest distributed cloud computing network with 11,000+ daily GPUs and 450,000 GPUs contributing compute, all at the lowest cost in the market.


