
Note: Do not miss out on listening to voice clones of 10 different celebrities reading Harry Potter and the Sorcerer’s Stone towards the end of the blog.
Introduction to MetaVoice-1B
MetaVoice-1B is an advanced text-to-speech (TTS) model boasting 1.2 billion parameters, meticulously trained on a vast corpus of 100,000 hours of speech. Engineered with a focus on producing emotionally resonant English speech rhythms and tones, MetaVoice-1B stands out for its accuracy and realistic voice synthesis.
One standout feature of MetaVoice-1B is its ability to perform zero shot voice cloning. This feature requires only a 30-second audio snippet to accurately replicate American & British voices. It also includes cross-lingual cloning capabilities demonstrated with as little as one minute of training data for Indian accents. A versatile tool released under the permissive Apache 2.0 license, MetaVoice-1B is designed for long-form synthesis.
The architecture of MetaVoice-1B
MetaVoice-1B’s architecture is a testament to its innovative design. Combining causal GPT structures and non-causal transformers, it predicts a series of hierarchical EnCodec tokens from text and speaker information. This intricate process includes condition-free sampling, enhancing the model’s cloning proficiency. The text is processed through a custom-trained BPE tokenizer, optimizing the model’s linguistic capabilities without the need for predicting semantic tokens, a step often deemed necessary in similar technologies.
MetaVoice cloning benchmark methodology on SaladCloud GPUs
Encountered Limitations and Adaptations
During the evaluation, we encountered limitations with the maximum length of text that MetaVoice could process in one go. The default token limit is set to 2048 tokens per batch. However, we noticed that even with a smaller number of tokens, the model starts to act differently than expected. To solve the limit issue, we had to preprocess our data by dividing the text into smaller segments, specifically two-sentence pieces, to accommodate the model’s capabilities.
To break the text into sentences, we used Punkt Sentence Tokenizer.
The text source remained consistent with previous benchmarks, utilizing Isaac Asimov’s “Robots and Empire,” available from Internet Archive: Digital Library of Free & Borrowable Books, Movies, Music & Wayback Machine. For the voice cloning component, we utilized a one-minute sample of Benedict Cumberbatch’s narration.
The synthesized output very closely mirrored the distinctive qualities of Cumberbatch’s narration, demonstrating MetaVoice’s cloning capabilities, which are the best we’ve seen yet.
Here is a voice-cloning example featuring Benedict Cumberbatch:
GPU Specifications and Selection
MetaVoice documentation specifies the need for GPUs with VRAM of 12GB or more. Despite this, our trials included GPUs with lower VRAM, which still performed adequately. But this required a careful selection process from SaladCloud’s GPU fleet to ensure compatibility. We standardized each node with 1 vCPU and 8GB of RAM to maintain a consistent testing environment.
Benchmarking Workflow
The benchmarking procedure was incorporating multi-threaded operations to enhance efficiency. The process involved parallel downloading of parts of text and the voice reference sample from Azure and processing text through MetaVoice model. After completing the cycle, the resulting audio was uploaded back to Azure. This comprehensive workflow was designed to simulate a typical application scenario, providing a realistic assessment of MetaVoice’s operational performance on SaladCloud GPUs.
Benchmark Findings: Cost-Performance and Inference Speed
Words per Dollar Efficiency
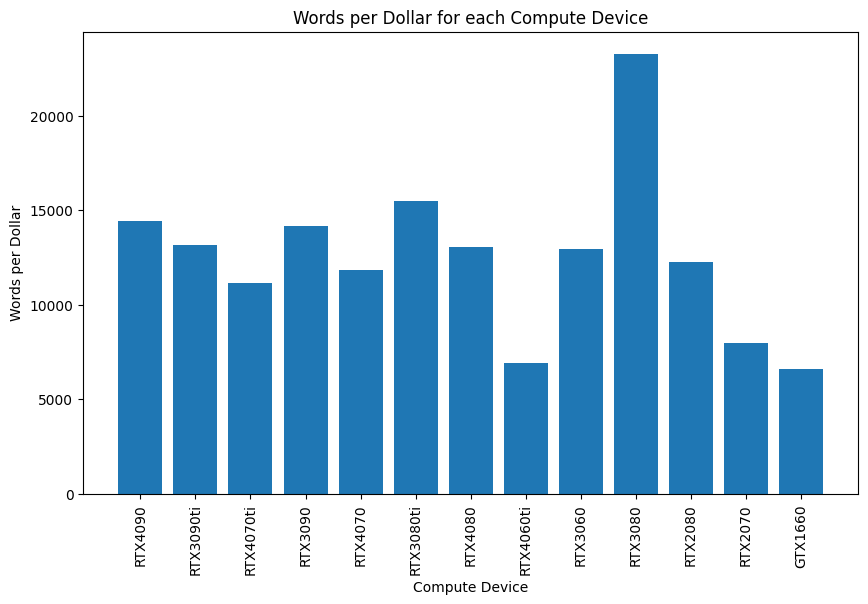
Our benchmarking results reveal that the RTX 3080 GPU leads in terms of cost-efficiency for MetaVoice, achieving an impressive 23,300 words per dollar. The RTX 3080 Ti follows closely with 15,400 words per dollar. These figures highlight the resource-intensive nature of MetaVoice, requiring powerful GPUs to operate efficiently.
Speed Analysis and GPU Requirements
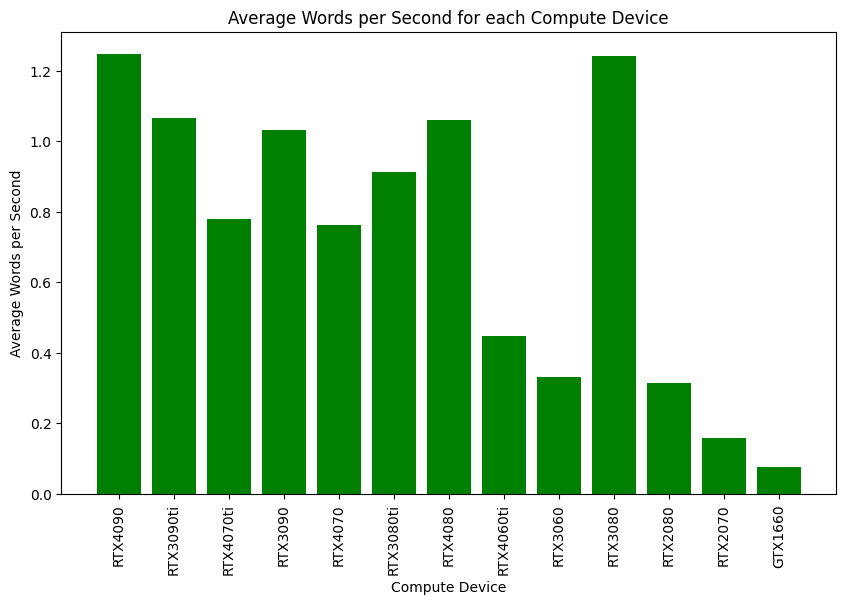
Our speed analysis revealed that GPUs with 10GB or more VRAM performed consistently, processing approximately 0.8 to 1.2 words per second. In contrast, GPUs with lower VRAM demonstrated significantly reduced performance, rendering them unsuitable for running MetaVoice. This aligns with the developers’ recommendation of using GPUs with at least 12GB VRAM to ensure optimal functionality.
Cost Analysis for an Average Book
To provide a practical perspective, let’s consider the cost of converting an average book into speech using MetaVoice on SaladCloud GPUs. Assuming an average book contains approximately 100,000 words:
- RTX 3080: At 23,300 words per dollar, the cost to convert an average book would be ~$4.29.
- RTX 3080 Ti: At 15,400 words per dollar, the cost would be ~$6.49.
Creating a narration of “Harry Potter and the Sorcerer’s Stone” by Benedict Cumberbatch would cost around $3.30 with an RTX 3080 and $5.00 with an RTX 3080 Ti.
Here is an example of a voice clone of Benedict Cumberbatch reading Harry Potter:
Notice that we did not change any model parameters or add business logic. We only added batch processing sentence by sentence.
We also cloned other celebrity voices to read out the first page of Harry Potter and the Sorcerer’s Stone. Here’s a collection of different voice clones reading Harry Potter using MetaVoice.
MetaVoice GPU Benchmark on SaladCloud – Conclusion
In conclusion, the combination of MetaVoice and SaladCloud GPUs presents a cost-effective and high-quality solution for text-to-speech and voice cloning projects. Whether for large-scale audiobook production or specialized projects like celebrity-narrated books, this technology offers a new level of accessibility and affordability in voice synthesis. As we move forward, it will be exciting to see how these advancements continue to shape the landscape of digital content creation.
SaladCloud suggests: If you are just looking to generate AI voices, give Veed.io’s AI voice generator a try. With AI voices and AI avatars, Veed.io will generate ultra-realistic text-to-speech audio/video for personal and commercial use.


