
In the field of Artificial Intelligence (AI), Text Generation Inference (TGI) has become a vital toolkit for deploying and serving Large Language Models (LLMs). TGI enables efficient and scalable text generation with popular open-source LLMs, including Llama, Falcon, StarCoder, BLOOM, GPT-NeoX, and Mistral. This SaladCloud benchmark dives deep into this technology, with a LLM comparison focused on the performance of popular language models.
TGI and Large Language Models
TGI is essential for leveraging the capabilities of Large Language Models, which are key to many AI applications today. These models, known for generating text that closely resembles human writing, are crucial for applications ranging from automated customer service to creative content generation.
You can easily deploy TGI on SaladCloud using the following instructions:
Run TGI (Text Generation Interface) by Hugging Face
Experiment design: Benchmarking on SaladCloud
Our benchmark study on SaladCloud aims to evaluate and compare select LLMs deployed through TGI. This will provide insights into model performance under varying loads and the efficacy of SaladCloud in supporting advanced AI tasks.
Models for comparison
We’ve selected the following models for our benchmark, each with its unique capabilities:
Test parameters
Batch Sizes: The models will be tested with batch sizes of 1, 4, 8, 16, 32, 64, and 128.
Hardware Configuration: Uniform hardware setup across tests with 8 vCPUs, 28GB of RAM, and a 24GB GPU card.
Benchmarking Tool: To conduct this benchmark, we utilized the Text Generation Benchmark Tool,
which is a part of TGI and designed to effectively measure the performance of these models.
Model Parameters: We’ve used the default Sequence length of 10 and decode length of 8.
Performance metrics
The TGI benchmark provides us with the following metrics for each batch we provided:
- Prefill Latency
- Prefill Throughput
- Decode (token) Latency
- Decode (total) Latency
- Decode throughput
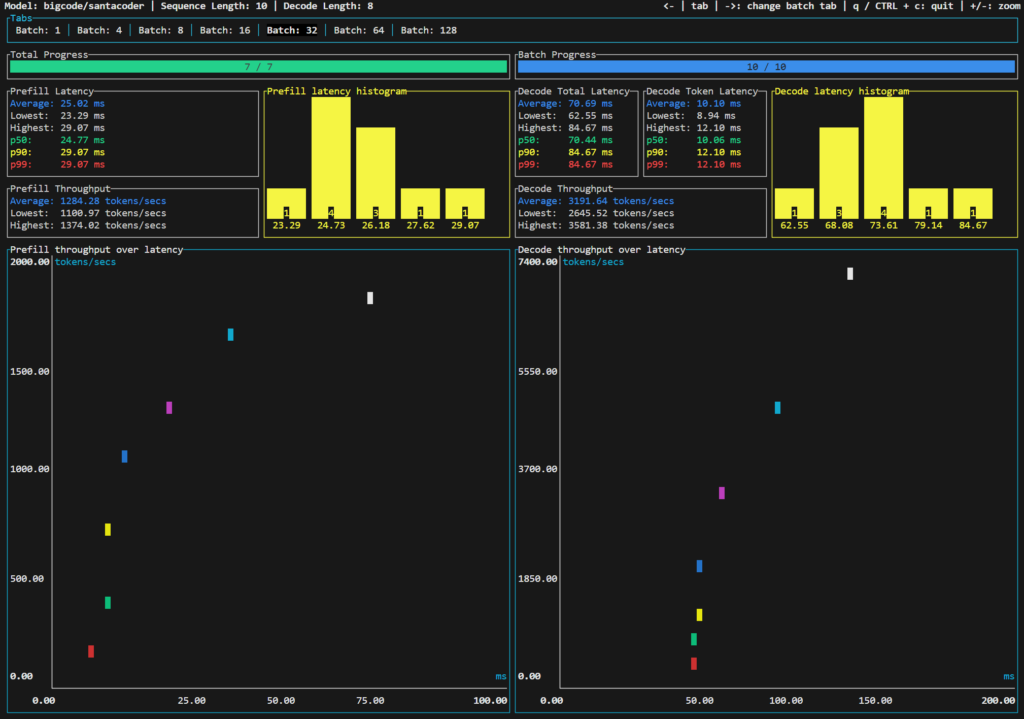
Bigcode/santacoder
bigcode/santacoder is part of the SantaCoder series, featuring 1.1 billion parameters and trained on subsets of Python, Java, and JavaScript from The Stack (v1.1). This model, known for its Multi Query Attention and a 2048-token context window, utilizes advanced training techniques like near-deduplication and comment-to-code ratio filtering. The SantaCoder series also includes variations in architecture and objectives, providing diverse capabilities in code generation and analysis. This is the smallest model in our benchmark.
Key observations
- Scalability with Batch Size: As the batch size increased, we observed a general trend of increased latency. However, the model scaled efficiently up to a certain point, beyond which the increase in latency became more pronounced.
- Optimal Performance: The model showed optimal performance in terms of both latency and throughput at mid-range batch sizes. Particularly, batch sizes of 16 and 32 offered a good balance between speed and efficiency. For our price-per-token calculation, we will take a batch of 32.
- Throughput Efficiency: In terms of tokens per second, the model demonstrated impressive throughput, particularly at higher batch sizes. This indicates the model’s capability to handle larger workloads effectively.
Cost-effectiveness on SaladCloud: bigcode/santacoder
A key part of our analysis focused on the cost-effectiveness of running TGI models on SaladCloud. For a batch size of 32, with a compute cost of $0.35 per hour, we calculated the cost per million tokens based on throughput :
- Average Throughput: 3191 tokens per second
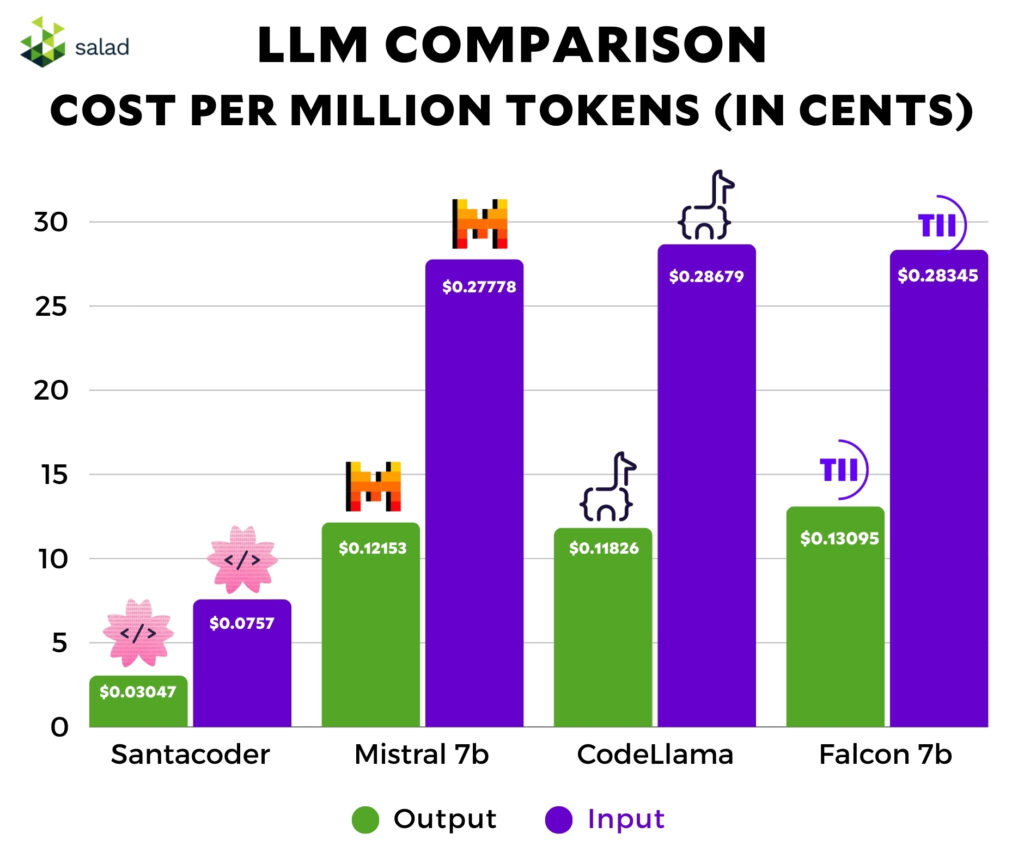
The cost per token, considering the throughput and compute price, is approximately $0.03047 or about 3.047 cents per million tokens for output and $0.07572 per million input tokens.
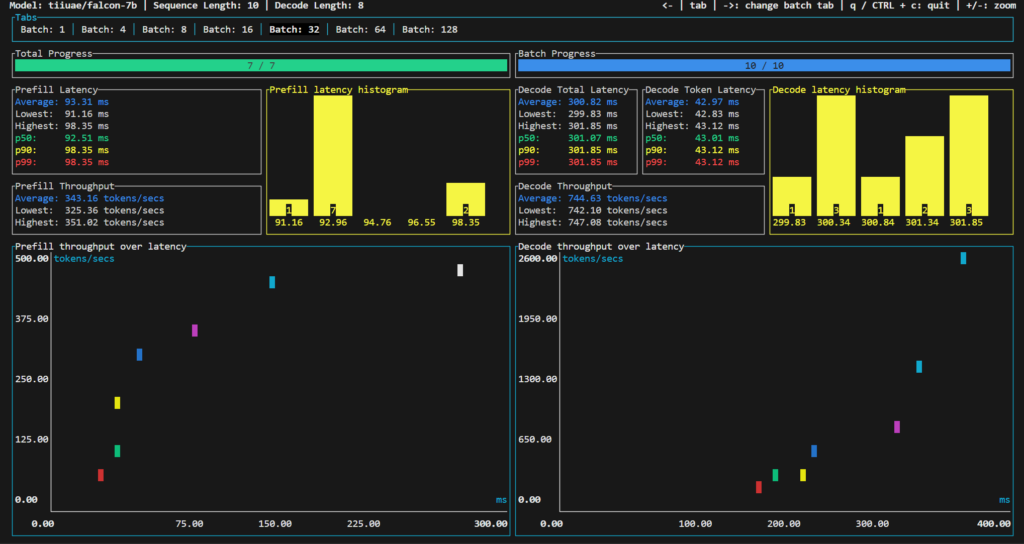
Tiiuae/falcon-7b
Falcon-7B is a decoder-only model with 7 billion parameters. It was built by TII and trained on an extensive 1,500B token dataset from RefinedWeb, enhanced with curated corpora. It is available under the Apache 2.0 license, making it a significant model for large-scale text generation tasks.
Key findings
- Latency Trends: As the batch size increased, there was a noticeable increase in average latency after batch 16.
- Throughput Efficiency: The throughput in tokens per second showed significant improvement as the batch size increased, indicating the model’s capability to handle larger workloads efficiently.
- Optimal Performance: The model demonstrated a balance between speed and efficiency at mid-range batch sizes, with batch sizes 16, 32, and 64 showing notable throughput efficiency.
Cost-effectiveness on SaladCloud: Tiiuae/Falcon-7b
For the tiiuae/falcon-7b model on SaladCloud with a batch size of 32 and a compute cost of $0.35 per hour, the calculated cost per million tokens with a throughput of 744 tokens per second is approximately $0.13095, or about 13.095 cents per million output tokens and $0.28345 per million input tokens.
The average decode total latency for batch size 32 is 300.82 milliseconds. While this latency might be slightly higher compared to smaller models, it still falls within a reasonable range for many applications, especially considering the model’s large size of 7 billion parameters.
The cost-effectiveness, combined with the model’s capabilities, makes it a viable option for extensive text generation tasks on SaladCloud.
Code Llama
Code Llama is a collection of generative text models, with the base model boasting 7 billion parameters. It’s part of a series ranging up to 34 billion parameters, specifically tailored for code-related tasks. This benchmark focuses on the base 7B version in Hugging Face Transformers format, designed to handle a wide range of coding applications.
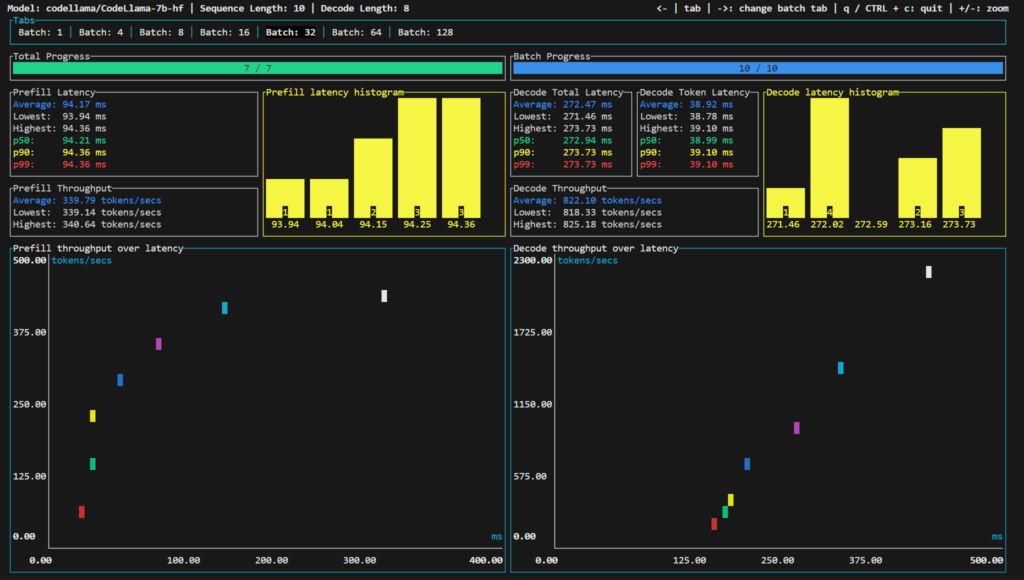
- Latency Trends: A gradual increase in latency was observed as the batch size increased, with the highest latency noted at batch size 128.
- Throughput Efficiency: The model displayed improved throughput efficiency with larger batch sizes, indicative of its ability to handle increasing workloads.
- Balance in Performance: Optimal performance, in terms of speed and efficiency, was noted at mid-range batch sizes.
The cost for processing one million tokens using the Code Llama model on SaladCloud, with a batch size of 32 and a compute cost of $0.35 per hour, is approximately $0.11826 per million output tokens and $0.28679 per million input tokens. This figure highlights the economic feasibility of utilizing SaladCloud for large-scale text generation tasks with sophisticated models like Code Llama.
Mistral-7B-Instruct-v0.1
Mistral-7B-Instruct-v0.1 is an instruct fine-tuned version of the Mistral-7B-v0.1 generative text model. This model leverages a variety of publicly available conversation datasets to enhance its capability to understand and generate human-like, conversational text. Its fine-tuning makes it particularly adept at handling instruction-based queries, setting it apart in the realm of LLMs.
- Throughput Achieved: Approximately 800 tokens per second with a batch of 32
- Average Latency: 305 milliseconds
Key insights
- High Throughput: The Mistral-7B-Instruct-v0.1 model demonstrates a strong throughput of about 800 tokens per second, indicating its efficiency in processing requests quickly.
- Latency: With an average latency of 305 milliseconds, the model balances responsiveness with the complexity of tasks it handles, making it suitable for a wide range of conversational AI applications.
Implications and Cost Analysis
The performance of the Mistral-7B-Instruct-v0.1 model on SaladCloud shows promising potential for its use in various AI-driven conversational systems. Its ability to process a high number of tokens per second at a manageable latency makes it a strong contender for applications requiring nuanced language understanding and generation.
With a price of $0.35 per hour, we achieve a cost of approximately $0.12153 per million output tokens and $0.27778 per million input tokens.
Conclusion – LLM comparison benchmark results
Our comprehensive LLM comparison benchmark of various Text Generation Inference (TGI) models on SaladCloud reveals an insightful trend: despite the diversity in the models’ capabilities and complexities, there is a remarkable consistency in cost-effectiveness when using the same compute configuration.
Consistent performance and cost-effectiveness
- Uniform Compute Benefits: Utilizing a uniform compute setup across different models like santacoder, Falcon-7b, Llama, and Mistral, we observed comparable efficiency in terms of tokens processed per second and a similar price range per million tokens. This consistency highlights the robustness and flexibility of SaladCloud’s infrastructure.
- Cost Per Token: On average, the cost per million tokens remains within a similar range from 10 to 14 cents per 1 million tokens across the three 7b models. This demonstrates that SaladCloud can efficiently handle a wide range of AI and machine learning tasks without significant cost variation, making it an ideal platform for diverse text generation needs.
Customizable compute options
- Enhanced Efficiency and Reduced Costs: One of the standout features of SaladCloud is its ability to configure the exact type of compute resources required for specific models. This customization means that for some models, it’s possible to achieve the same or better efficiency at a lower cost by optimizing the compute resources to the model’s specific needs.
Final thoughts
In conclusion, SaladCloud emerges as a compelling choice for deploying and running TGI models. Its ability to provide uniform compute efficiency across a range of models, combined with the option to customize and optimize compute resources, offers both consistency in performance and flexibility in cost management.
Whether it’s for large-scale commercial deployments or smaller, more targeted AI tasks, SaladCloud’s platform is well-equipped to meet diverse text generation requirements with an optimal balance of efficiency and cost-effectiveness
SaladCloud is the world’s largest distributed cloud computing network with 11,000+ daily GPUs and 450,000 GPUs contributing compute, all at the lowest cost in the market.


