
In recent times, JupyterLab has gained popularity among data scientists and students because of its ease of use, flexibility, and extensibility. However, access to resources and cost remain a hindrance. In this blog, we provide a walkthrough on creating and running your own GPU-accelerated JupyterLab, taking advantage of low GPU prices on SaladCloud.
The challenge in data science learning & research
Many college students and professionals in the AI and Data Science industry face common challenges when dealing with GPU-capable development environments for learning, testing, or researching.
The laptops they use daily often lack a dedicated GPU, or the built-in GPUs are incompatible with popular frameworks like TensorFlow and PyTorch. Investing in a second computer with an NVIDIA GPU for Machine Learning not only costs thousands of dollars but also results in low utilization and inconvenience.
In addition, building development environments using NVIDIA GPUs could be tedious work. One needs to be familiar with Windows, Linux, or both; understand the version compatibility among different software pieces; and know how to install Python and its IDE, TensorFlow/PyTorch, C/C++ Compiler, cuDNN, CUD, and the GPU Driver, etc. The process can be frustrating and time-consuming. Many individuals spend several days reading instructions and seeking help online, hindering research and learning progress.
While public cloud providers offer options with GPU-capable compute instances or managed services, these solutions work well for enterprise customers training and deploying large AI models in production environments.
However, they are too expensive and overkill for personal learning or testing, with prices ranging from $0.50 to tens of dollars per hour. Moreover, the services from these public cloud providers are becoming more and more complicated, and many services are intertwined and built on top of others. To start working on AI and Data Science using these public clouds, you likely need several weeks first to gain a basic understanding of how these services work together.
The JupyterLab solution
This is where a tool like JupyterLab is becoming increasingly popular as the standard for learning & researching in data science. JupyterLab is a web-based interactive development environment for notebooks, code, and data. It is designed to provide a flexible and powerful platform for data science, scientific computing, and computational workflows.
JupyterLab is the next generation of Jupyter Notebook, which is one of the most popular IDEs for data science. It offers more features, flexibility, and integration than the classic Jupyter Notebook. But accessing and running JupyterLab on public clouds still requires significant time and financial commitment.
Easy, affordable access to JupyterLab on SaladCloud
SaladCloud is the world’s largest community-powered cloud, connecting unused compute resources with GPU-hungry businesses. By running JupyterLab on a distributed cloud infrastructure like SaladCloud, you can now learn data science at a more affordable cost. With more than a million individuals sharing compute and 10,000+ GPUs available at any time, SaladCloud offers consumer-grade GPUs at the lowest market prices compared to any other cloud. Prices start from $0.02/hour. You can view the complete list of GPU prices here.
SaladCloud is very straightforward and easy to use: with pre-built container images, you can swiftly launch publicly-accessible, elastic and GPU-accelerated container applications within a few minutes.
By building and running JupyterLab container images with popular AI/ML frameworks, we can transform SaladCloud into an ideal platform for college students and professionals to:
- learn Shell, C/C++, CUDA, and PyTorch/TensorFlow programming,
- to test and research various AI models for training, fine-tuning, and inference,
- and to share insights and collaborate with peers.
Cost analysis of running JupyterLab on SaladCloud
Here are the typical use cases running JupyterLab on SaladCloud and a cost analysis for each:
| Resource Type | Use Cases | Public Cloud Providers | SaladCloud |
|---|---|---|---|
| 2vCPU, 4 GB RAM, GPU with 4 GB VRAM | Learning programming with Shell, C/C++, CUDA, PyTorch/TensorFlow, and Hugging Face. | N/A | $0.032 per hour |
| 4vCPU, 16 GB RAM GPU with 16 GB VRAM | Most NLP and CV tasks including testing, training and inference. | $0.5+ per hour, Additional charge on network traffic. | $0.31 per hour, 40% Saving |
| 8vCPU, 24 GB RAM GPU with 24 GB VRAM | Testing, fine-tuning and inference for the latest LLM and Stable Diffusion, etc. | $1.2+ per hour, Additional charge on network traffic. | $0.36 per hour, 70% Saving |
Several JupyterLab container images have been built to meet general AI/ML requirements. The corresponding Dockerfiles are also available on the GitHub repository, allowing SaladCloud users to tailor these images to specific needs.
Resources:
- JupyterLab user guide
- Docker Hub Repository for JupyterLab
- GitHub Repository for JupyterLab on SaladCloud
How to deploy JupyterLab on SaladCloud
SaladCloud is designed to execute stateless container workloads. To preserve code and data while using JupyterLab, it is imperative to set up the cloud-based storage and integrate it with the JupyterLab containers. We have already integrated the major public cloud platforms, including AWS, Azure, and GCP, into the pre-built container images. There are also detailed instructions on how to provision storage services on these platforms. With these integrations, the JupyterLab instances running on SaladCloud support data persistence, ensuring that changes in code and data are automatically saved to the cloud.
For more information on how these images are built and integrated with public cloud providers, please refer to the user guide.
Deploy the JupyterLab instance
Let’s run a JupyerLab container instance on SaladCloud to see what it looks like. In this instance, we utilize AWS S3 as the backend storage. The AWS S3 bucket/folder has already been provisioned, and the access key ID and secret access key have been generated. This step can be omitted if data persistence in the container is not necessary.
Log in to the SaladCloud Console and deploy the JupyterLab instance by selecting ‘Deploy a Container Group’ with the following parameters:
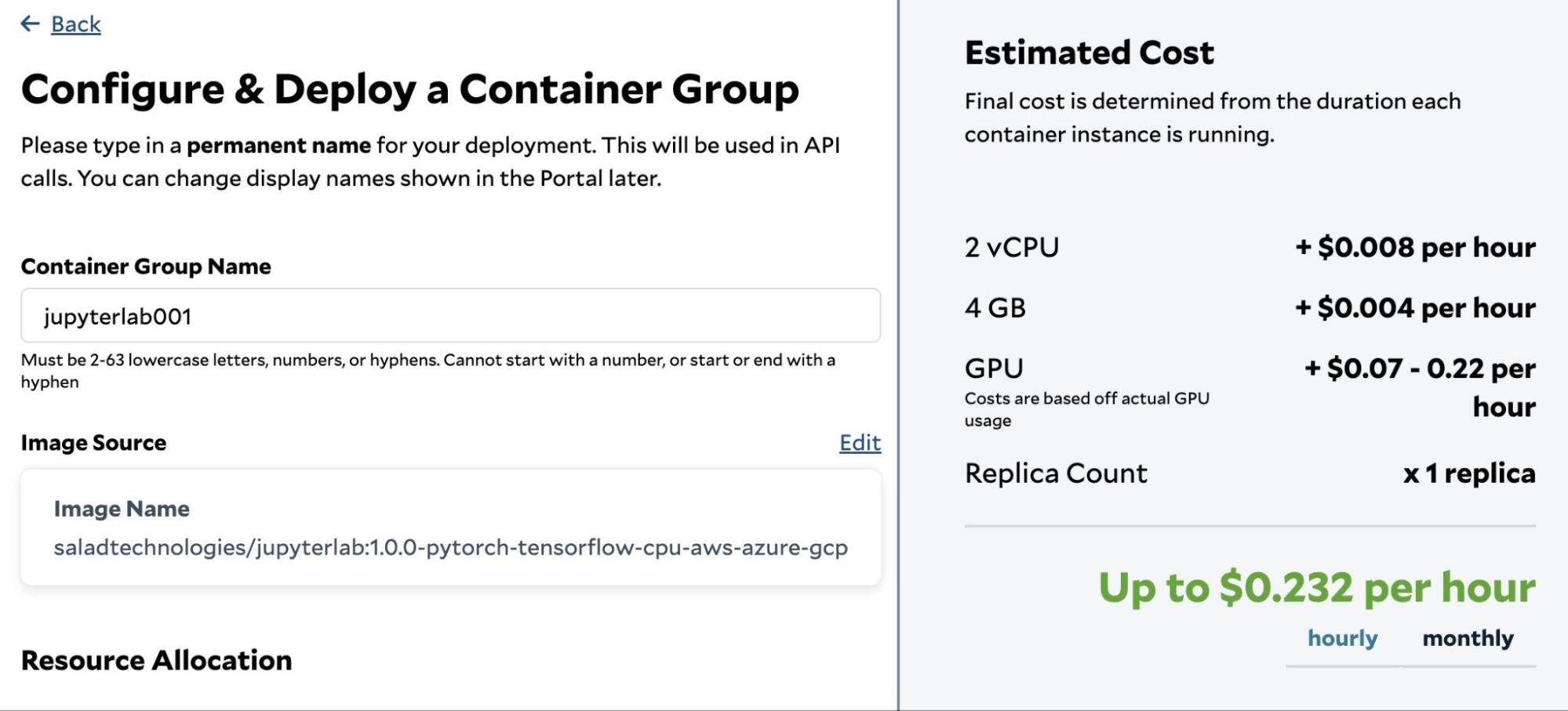
| Parameter | Value |
| Container Group Name | jupyterlab001 |
| Image Source | saladtechnologies/jupyterlab:1.0.0-pytorch-tensorflow-cpu-aws-azure-gcp |
| Replica Count | 1 |
| vCPU | 2 |
| Memory | 4 GB |
| GPU | RTX 1650 (4 GB), RTX 2080 (8 GB), RTX 4070 (12 GB) # We can choose multiple GPU types simultaneously, and SaladCloud will then select a node that matches one of the selected types. |
| Networking | Enable, Port: 8000 Use Authentication: No |
| Environment Variables | JUPYTERLAB_PW AWS_ACCESS_KEY_ID AWS_SECRET_ACCESS_KEY AWS_S3_BUCKET_FOLDER |
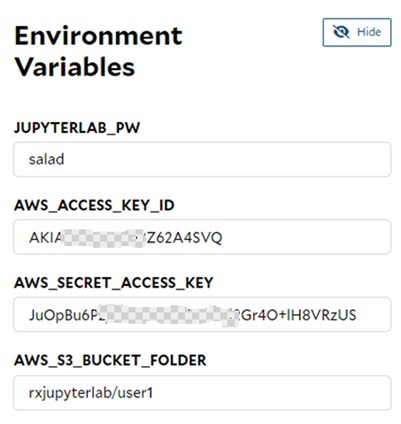
Setup the environment variables
The default password for JupyterLab will be ‘data’ if we don’t provide the environment variable – ‘JUPYERLAB_PW’, and the other 3 AWS-related environment variables can be omitted if the data persistence is not required.
Run and access the JupyterLab instance
SaladCloud would take a few minutes to download the image to the selected node and run the container. By using the SaladCloud Console, we can determine whether the JupyterLab instance is ready to use.
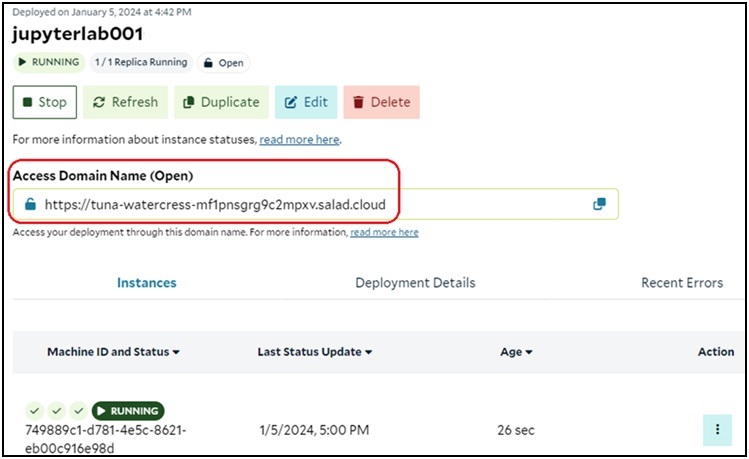
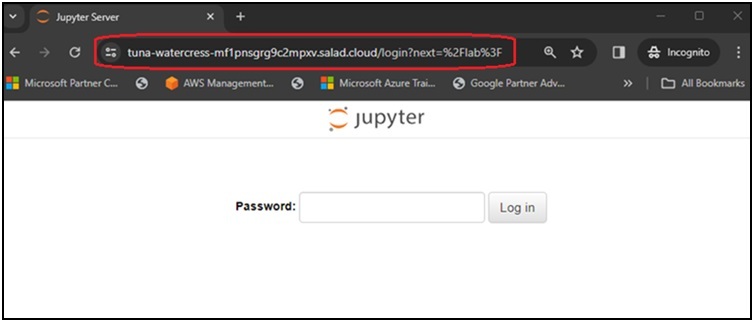
After the instance is running, we can type the generated Access Domain Name in the browser’s address bar, enter the password provided by the environment variable – JUPYTERLAB_PW, and begin using the JupyterLab service.
The current working directory of the JupyterLab instance is configured to the /root/data, and it is continuously monitored by a background process. Upon the initial launch of the instance, all data is synchronized from the selected cloud platform to the /root/data directory. Subsequently, any changes made in this directory and its subfolders will be automatically synchronized back to the cloud platform. This implies that the manual saving of files through the JupyterLab menu or automatic saving by JupyterLab’s autosave feature in the background will trigger the synchronization.
Models and datasets that are dynamically downloaded from Hugging Face or TensorFlow Hub are stored in the /root/.cache or /root/.keras hidden folders. These data will be not synchronized to the cloud platform unless they are explicitly saved into the /root/data directory.
Considering that AWS S3 incurs a charge of $0.023 per GB Month (similar across all three cloud providers), the associated cost becomes negligible by utilizing AWS S3 for storing code rather than models and datasets, which can be dynamically downloaded while using the container.
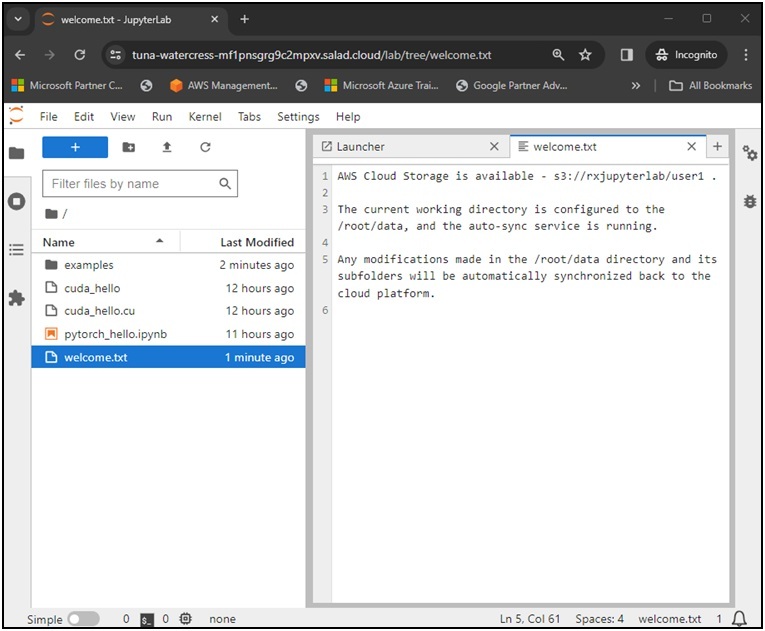
Use Python code to accomplish tasks
Now, it’s time to leverage JupyterLab to accomplish tasks. We can write Python code to learn, test, fine-tune, or train the popular AI models from Hugging Face. In case any libraries or dependencies are missing, we can install them online in the notebook or terminal. SaladCloud users can also build their own container images to include specific libraries and dependencies based on the provided Dockerfiles.
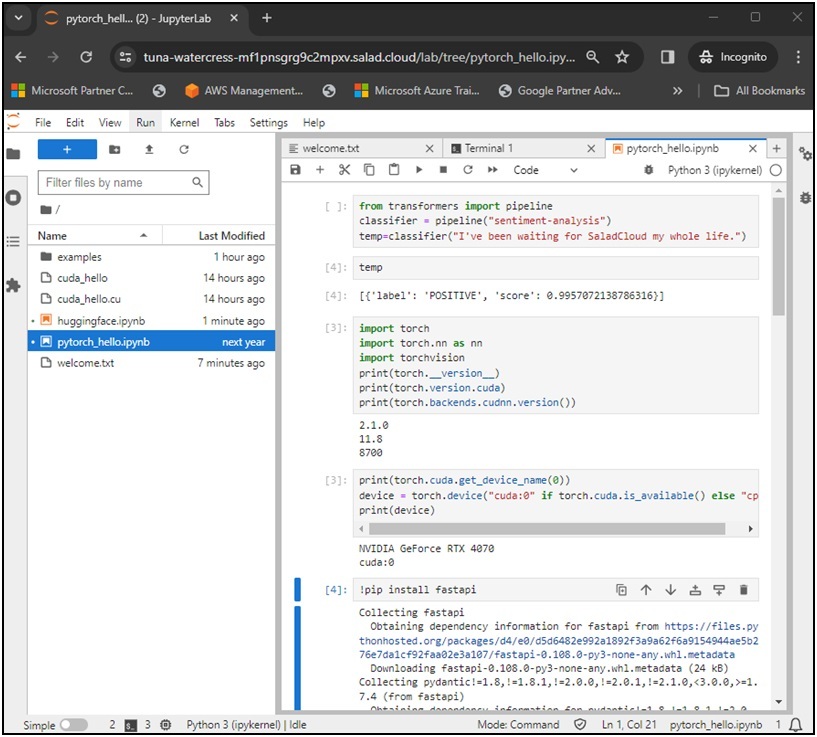
In the JupyterLab terminal, we have the flexibility to use SH and BASH and switch between them. Additionally, we can engage in C/C++ and CUDA programming by utilizing gcc and nvcc.
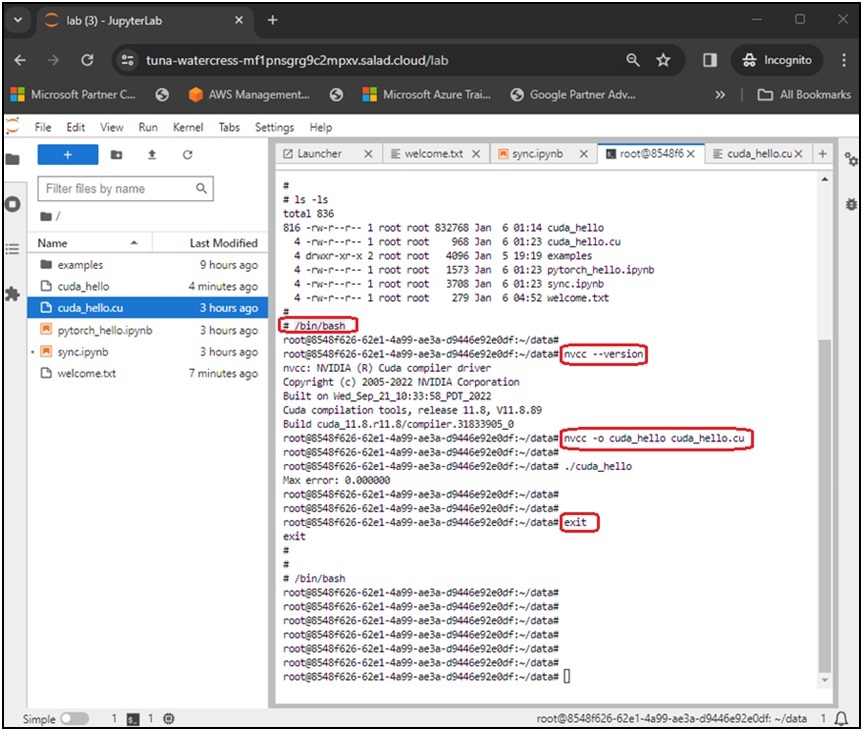
By sharing access to the JupyterLab instance, a team can collaborate on editing the same notebook or using the same terminal from different locations. If we find ourselves stuck with code or are unsure about certain Linux command-line tasks, we can bring in our friends for assistance. Regarding the JupyterLab terminal, any modifications made by other team members in the terminal will promptly reflect in our browser and vice versa, similar to screen sharing on WebEx or Zoom.
Making JupyterLab affordable for students and researchers
By leveraging JupyterLab over SaladCloud, students and professionals can easily learn, test & research various AI models at a low cost. This also helps reduce the time and effort associated with building dedicated development environments. In addition, one can easily share insights and collaborate with peers, thereby accelerating the speed and innovation in the field of AI.
SaladCloud will consistently update the JupyerLab images to incorporate more features and include more popular libraries and code examples. If you have any questions or specific requirements about running JupyterLab on SaladCloud, please let us know.
Resources:
- JupyterLab user guide
- Docker Hub Repository for JupyterLab
- GitHub Repository for JupyterLab on SaladCloud
SaladCloud is the world’s largest distributed cloud computing network with 11,000+ daily GPUs and 450,000 GPUs contributing compute, all at the lowest cost in the market.


