
What is AI Bias in Image Generation?
Type in ‘An engineer smiling at the camera’ as the prompt into a few AI image generators. What do you see? A collection of men in most cases. In a recent experiment, 298 out of the 300 stable diffusion-generated images were of perceived men for the prompt ‘Engineer.’ A similar racial/gender bias exists across many AI image generators and models today.
AI bias is the phenomenon of artificial intelligence systems producing results that are skewed or unfair towards certain groups or individuals, based on factors such as race, gender, age, or religion. This can occur due to various reasons, such as data bias, algorithm bias or human bias.
As the use of AI grows, bias can have serious negative consequences for individuals and society, such as violating human rights, perpetuating social inequalities, and undermining trust in AI systems.
While the pervasive bias in AI systems has been spotlighted time and again, especially in the art world, its nuances remain elusive. To explore this, we built our own AI portrait generator from scratch, delving into the subtle ways bias sneaks in and strategizing on crafting prompts to counteract it.

Our tool of choice is Dreamup.ai, a completely free AI image generator that shares 30% of its proceeds with artists. We’ll harness the power of the renowned Dreamshaper model. But let’s clear the air first: our pick is based on its stellar image quality and soaring popularity, not because it stands out as more or less biased than its counterparts—it doesn’t. Let’s get started!
Creating the AI Portrait Generator
For this experiment, we will create a Portrait Generator that transforms any given face into a salad, inspired by the 16th-century Italian painter Giuseppe Arcimboldo.

For this project, we’ll also use ControlNet and Depth Estimation. The process involves taking the 3D structure from an input image and using it, along with a prompt, to produce the final image. This method allows us to create a portrait generator without the need to train a LoRA model from scratch.
Step 1: Preparing the Reference Image – Turning a Face into a Salad
To start, we’ll use the Dreamshaper model to generate our reference image.
Prompt: stunning photograph of a handsome man in a business suit, portrait, city sidewalk background, shallow depth of field
Right off the bat, we see a bias issue. The prompt didn’t mention race, but all the generated images are of white men with brown hair, all striking a similar pose with a hand in the left pocket.
This lack of diversity stems from the fact that these models are primarily trained on images with English captions, reflecting the biases of English-speaking regions. As our aim is to highlight how biases manifest, let’s adjust our prompt to get a more diverse result.


Prompt: stunning photograph of a handsome black man in a business suit, portrait, city sidewalk background, shallow depth of field
By specifying race, we get a more diverse image, though the hand-in-pocket pose remains consistent. This suggests that our prompt might be triggering certain cultural or stylistic associations. However, we won’t delve into that now.
To ensure authenticity, let’s use a real stock photo as the reference image.
Fortune Vieyra in a black business suit, standing by a wall.
Source: https://unsplash.com/photos/aAN9ocBHbyo
Interestingly, even in this real photo, the hand-in-pocket pose persists.

Step 2: Extracting the Depth Map

Next, we’ll employ MiDaS Depth Estimation to derive a depth map from our reference image. This depth map will provide us with a 3D perspective of the reference, which is crucial for generating our final artwork. From the depth map, we can discern the structure and layout of the image. However, the color data is absent. This lack of color might pose challenges in the subsequent steps.
Depth map derived from our reference image
Step 3: Crafting the Perfect Prompt
Our first attempt will be a neutral prompt devoid of any racial or gender specifics.
Prompt: Detailed portrait of a person in the ((style of Giuseppe Arcimboldo)), face made of vegetables
As expected, the generated images predominantly feature white men, maintaining the composition of the reference. This could be due to the inherent model bias or the historical context of Arcimboldo, a European artist from the 16th century. To achieve our desired outcome, we’ll need to refine our prompt.


Prompt: Detailed portrait of a black man in the ((style of Giuseppe Arcimboldo)), face made of vegetables
By specifying the race, we get closer to our reference image. However, the overall image is notably darker. This might be due to the encoding process of the text, which can lose intricate details.
Prompt: Detailed portrait of an African American man in the ((style of Giuseppe Arcimboldo)), face made of vegetables
Switching “black” for “African American” yields a lighter image, but the generated faces are of lighter-skinned individuals. This could reflect a broader spectrum of skin tones or a potential cultural bias.

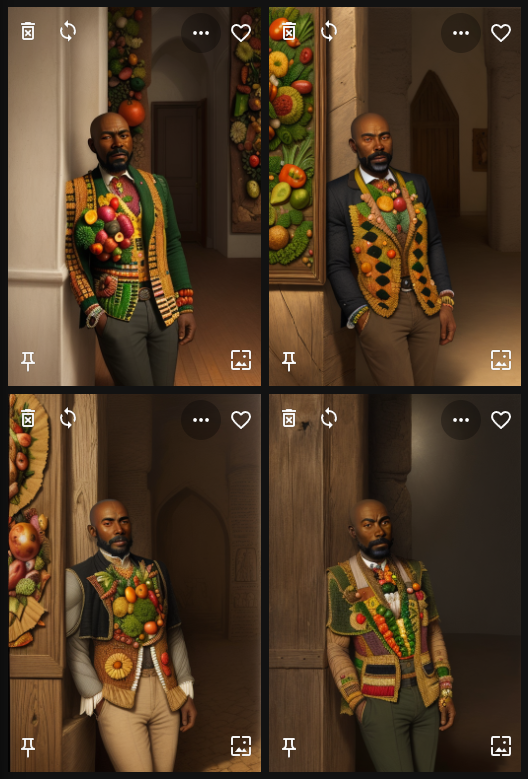
Prompt: Detailed portrait of an african man in the ((style of Giuseppe Arcimboldo)), face made of vegetables
Requesting an “African” man gives us darker skin tones, but the backgrounds seem less opulent. This might inadvertently introduce cultural stereotypes. Also, the vegetable face aspect is still missing.
Prompt: Detailed portrait of an african aristocratic man in the ((style of Giuseppe Arcimboldo))
Incorporating “aristocratic” brings back the grandeur in the backgrounds. Yet, the vegetable face remains elusive.


Prompt: Detailed ((vegetable painting)) of an african aristocratic man in the ((style of Vertumnus by Guiseppe Arcimboldo))
Negative Prompt: (((skin)))
Despite multiple attempts, achieving a vegetable-composed face proves challenging. It might be beneficial to use a closer reference image focusing solely on the face for better results.
New Reference Image, Depth Map, and Prompt
Reference image (Photo by Prince Akachi on Unsplash) and New Depth Map


With a fresh reference image of a young black woman and an updated depth map, our goal remains: a vegetable-composed face.
Prompt: Detailed ((vegetable painting)) of an african aristocratic woman in the ((style of Vertumnus by Guiseppe Arcimboldo))
Negative Prompt: (((skin)))
Interestingly, the generated images appear older than our reference. This unintended age bias surfaces despite the absence of age-related cues in our prompt.
Prompt: Detailed ((vegetable painting)) of a young african aristocratic woman in the ((style of Vertumnus by Guiseppe Arcimboldo))
Negative Prompt: (((skin)))
While the age factor improves, the resemblance to the reference remains elusive. Knowing our subject’s Nigerian origin, let’s incorporate that detail, along with “attractive,” for a more flattering portrayal.


Prompt: Detailed ((vegetable painting)) of an attractive young Nigerian aristocratic woman in the ((style of Vertumnus by Guiseppe Arcimboldo))
Negative Prompt: (((skin)))
However, the addition of “attractive” seems to have introduced an unintended sexualized portrayal, emphasizing the bust area. To counteract this, we’ll employ negative prompts.
Prompt: Detailed ((vegetable painting)) of an attractive young Nigerian aristocratic woman in the ((style of Vertumnus by Guiseppe Arcimboldo))
Negative Prompt: (((skin))) (((cleavage)))
We’re definitely getting closer to what we want, though there’s still not as many face vegetables as I want. At this point I’m suspecting that the MiDaS depth map is essentially forcing a smooth face, thus preventing the portrayal of the face as vegetables. Let’s try a different approach.

Step 4: Re-think Our ControlNet Selection

Of these, I would say the Lineart – Anime annotator and controlnet are producing the vegetable-iest results, despite the addition of a beard-like structure, which we also see in the Scribble version. This can probably be attributed to the artist, as most of Giuseppe Arcimboldo’s portraits feature beards. Let’s try adding a beard to the negative prompt with the Lineart – Anime controlnet.

Prompt: Detailed ((vegetable painting)) of a young african aristocratic woman in the ((style of
Vertumnus by Guiseppe Arcimboldo))
Negative Prompt: (((skin))) (((cleavage))) (beard)
We successfully dropped the beard, but the overall vegetable-ness has decreased. Let’s try adding some specific vegetables to the prompt.
Prompt: Detailed ((vegetable painting)) of attractive young nigerian aristocratic woman in the ((style of
Vertumnus by Guiseppe Arcimboldo)), carrot, tomato, beet, celery
Negative Prompt: (((skin))) (((cleavage))) (((beard)))
Finally, we’re inching closer to our envisioned output. Yet, the journey underscores the complexities of crafting a universally applicable workflow. The need to specify age, race, and gender and employ negative prompts to counteract biases makes the process intricate. This highlights the challenges in creating a one-size-fits-all
solution, especially when aiming for personalized and unbiased results.

Mitigating Bias in AI Image Generation
Our journey into the realm of AI image generation has shed light on the multifaceted nature of bias within these systems. While prompts offer a powerful tool to guide and refine AI outputs, crafting the perfect prompt is no simple task. It’s a delicate balance of specificity and generalization, often requiring multiple iterations to achieve the desired result.
The challenges we faced underscore the importance of diversity—in both the teams developing AI systems and the datasets they’re trained on. A broader spectrum of perspectives can help identify and rectify biases that might otherwise go unnoticed.
Furthermore, our exploration revealed the intricacies of text encoding in AI systems. The loss of nuanced information during this process can lead to outputs that deviate from our expectations. As users and developers, a deep understanding of the underlying mechanisms of our chosen AI tools is crucial. It empowers us to anticipate potential pitfalls and adapt our approach accordingly.
In essence, while AI offers immense potential, it’s imperative to approach it with a discerning eye, a willingness to iterate, and a commitment to inclusivity and fairness.


