
Stable Diffusion XL (SDXL) fine-tuning as a service
I recently wrote a blog about fine-tuning Stable Diffusion XL (SDXL) on interruptible GPUs at low cost, starring my dog Timber. The strong results and exceptional cost performance got me wondering: What would it take to turn that into a fully managed Stable Diffusion training platform?
I built one on SaladCloud to find out. The result? Costs as low as $0.0001019 per training step (at batch pricing) while successfully completing 1000/1000 training jobs.

Challenges in developing a Stable Diffusion API
There are a number of challenges involved when developing and deploying what’s essentially a Stable Diffusion XL training API on a distributed cloud like SaladCloud. SaladCloud is a distributed cloud with a Million+ individual PCs around the world connected to our network. The GPUs on SaladCloud are latent Nvidia RTX/GTX series. Our goal is for the service to be resilient at any kind of scale.
- Training nodes can be interrupted at any time with no warning
- We expect a number of submitted training jobs that dramatically exceed our capacity to simultaneously run them.
- Training jobs are long, from minutes to hours.
- Training nodes are too expensive to run while idle whenever we can help it.
- Training nodes can have a very long, cold start time.
- It is possible, though not common, for a training node to be “bad” for a variety of reasons.
- We want to handle downloading training data and uploading model checkpoints as securely as possible.
- We want observability in training jobs as they run.
- We want the platform as a whole to be very easy to operate, meaning it is doable for one person. In this case, that one person is me.
Architecture
To handle node interruptions and concurrent training, we built a simple orchestration API, with training compute handled by GPU worker nodes. Additionally, we setup a simple autoscaler using a scheduled Cloudflare Worker. Except for the pool of training nodes, the entire platform uses Cloudflare serverless services. This pattern is implemented in Kelpie in case you don’t want to build it from scratch.
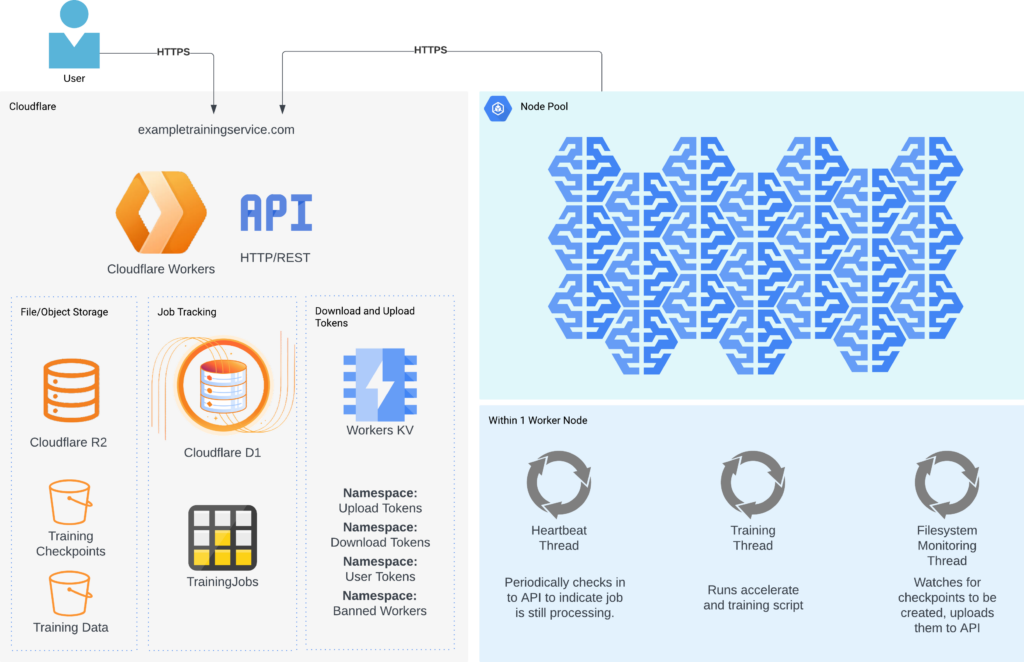
Heavily leveraging serverless technologies for the platform layer greatly reduces operational labor, makes the platform nearly free at rest, and will comfortably scale to handle significantly more load. Given sufficient continuous load, serverless applications do tend to be more expensive than alternatives, so feel free to swap out components as desired. This design doesn’t rely on any provider-specific features, so any SQL database and any Key-Value store would work just as well.
API components
- Cloudflare Workers as a serverless runtime
- itty-router-openapi to implement a lightweight OpenAPI-compatible REST API in the worker’s environment
- Cloudflare D1 as a serverless SQL database to track jobs
- Cloudflare R2 as egress-free storage of training data and training checkpoints
- Cloudflare Workers KV to store and manage short-lived upload and download tokens, handle API keys, and track potentially bad nodes.
GPU worker node components
- 🤗 Accelerate to run the training script
- Dreambooth LoRA SDXL training script from 🤗diffusers repository
- Stable Diffusion XL as the base image generation model
- SDXL VAE FP16 Fix as a replacement VAE to enable decoding in fp16
- 3 Threads:
- One thread to run the training script in a subprocess
- One thread to periodically heartbeat the API, letting it know the job is still running
- One thread to monitor the filesystem for checkpoint creation and upload those checkpoints
Distributing work
To get work, worker nodes make a GET request to the API, including their machine id as a query parameter. The API prioritizes handing out that are in the running state, but stalled as measured by heartbeat timeout. It also will never hand a job out to a node where that job has previously failed.
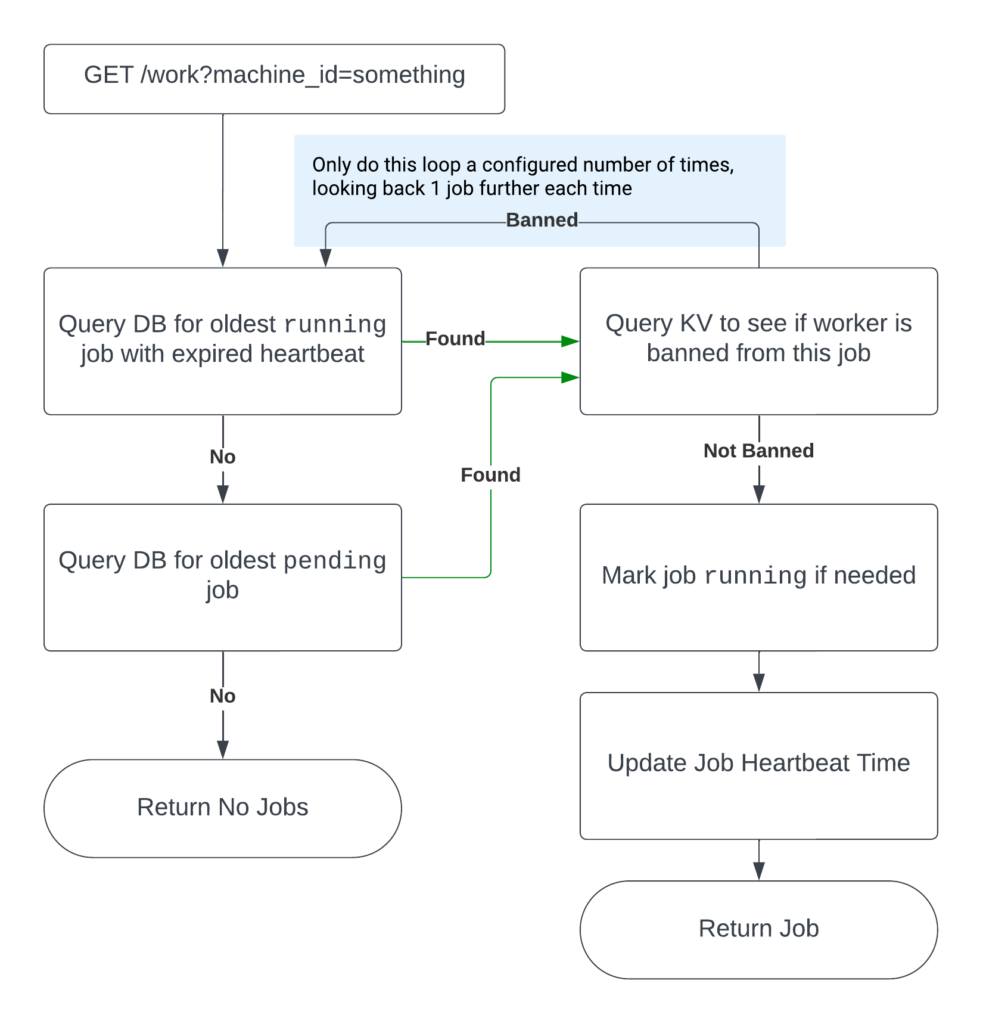
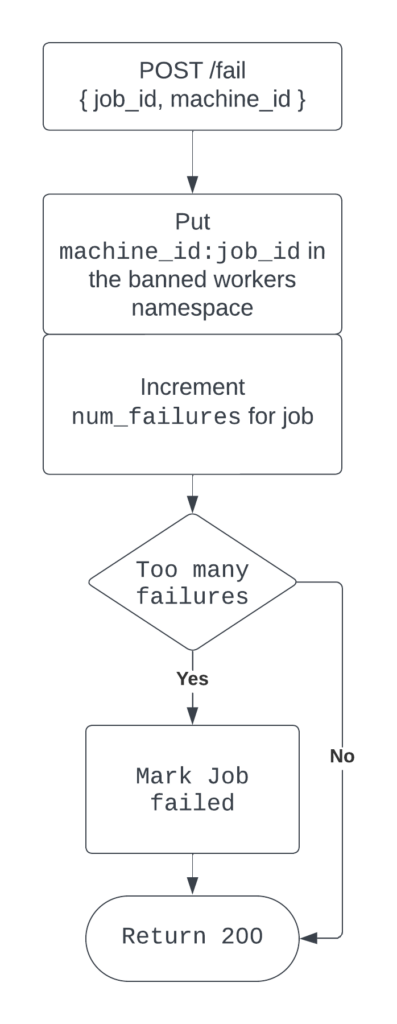
Marking a job failed
There are many reasons a job can fail, and some of those reasons are specific to a particular node, such as out-of-date drivers, inadequate available vRAM, and more. When this occurs, and the worker process is still alive, it makes a POST request to a fail endpoint, indicating the job has failed.
When this happens, the API does a few things:
- This machine is banned from processing this job again.
- If the job has received too many failure events, the job will be marked as
failed. Otherwise, it staysrunningso that it will be handed out again to a different node.
Handling bad nodes
If a particular node has failed too many jobs, we want to reallocate it. Our first implementation did not take this into account, and one bad node marked 85% of the benchmark failed, just pulling and failing one job after another. We now run a scheduled Cloudflare Worker every 5 minutes to handle reallocating any nodes with more than the allowed number of failures.
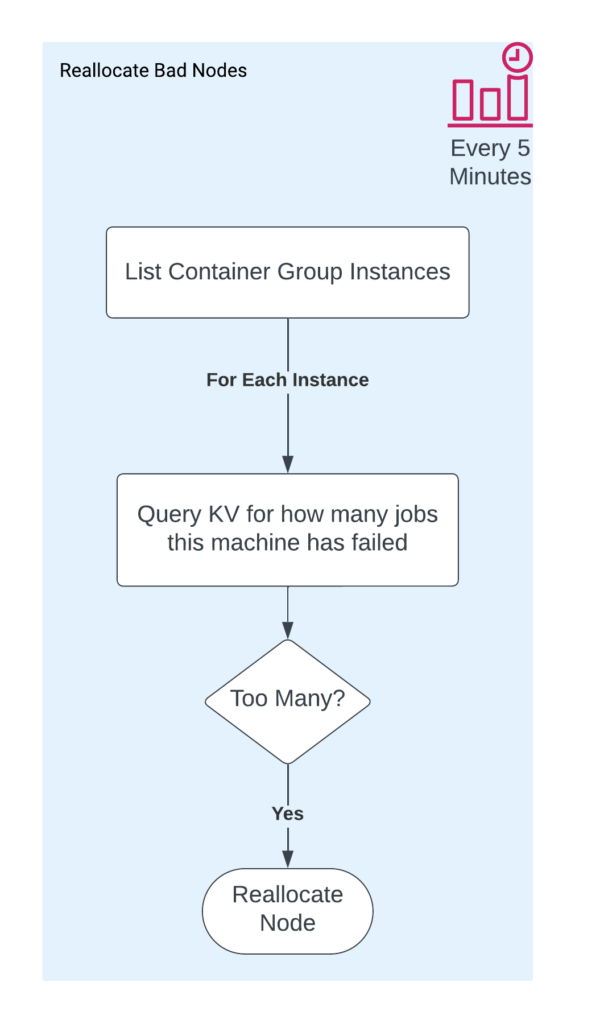
Autoscaling the worker pool
Our scheduled Cloudflare Worker also handles scaling the worker cluster. It essentially attempts to keep the number of replicas equal to the number of running and pending jobs, with configurable limits.
Observing a training run
The training script we used from diffusers has a built-in integration with Weights and Biases, a popular ML/AI training dashboard platform. It lets you qualitatively observe the training progress, track your training arguments, monitor system usage, and more.
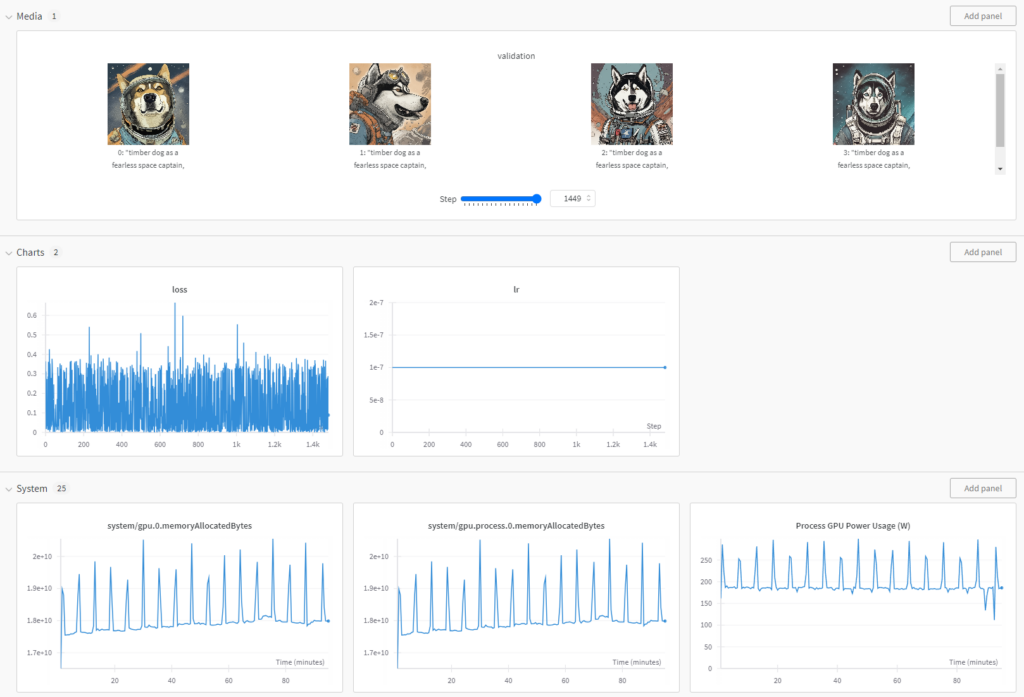
Deployment on SaladCloud
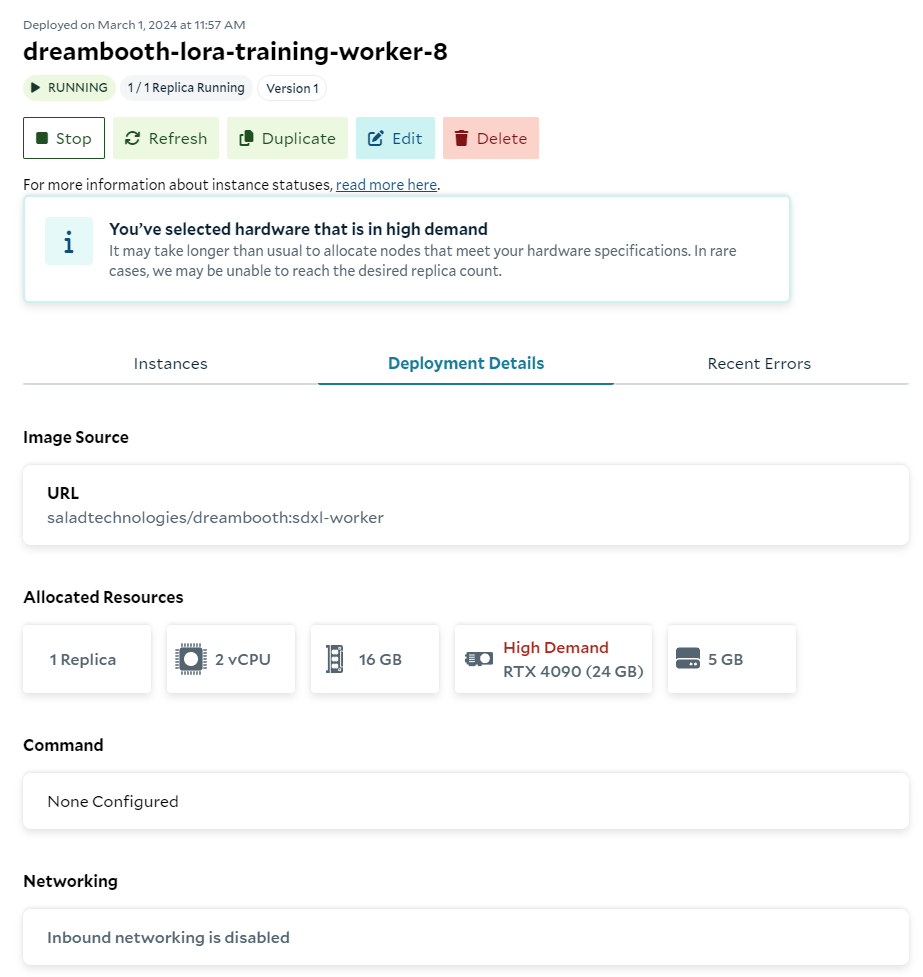
Deploying on SaladCloud is simple. The worker pattern means we don’t need to enable inbound networking or configure any probes. The only environment configuration needed is a URL for the orchestration API, a key for the orchestration API, and an API key for Weights and Biases (optional).

Seeding the benchmark
To get a baseline idea of performance, we ran 1000 identical training jobs, each 1400 steps, with text encoder training. We skipped reporting samples to Weights and Balances for this benchmark. We let the auto-scaler run between 0 and 40 nodes each with 2 vCPU, 16GB RAM, and an RTX 4090 GPU.
if [[ -z $API_KEY ]]; then
echo "API_KEY is not set"
exit 1
fi
num_jobs=1000
for i in $(seq 1 $num_jobs); do
curl -X POST \
'https://sdxl.dreambooth.run/job' \
--header "x-api-key: $API_KEY" \
--header 'Content-Type: application/json' \
--data-raw '{
"instance_prompt": "a photo of timber dog",
"instance_data_prefix": "timber/",
"max_train_steps": 1400,
"learning_rate": 0.0000001,
"checkpointing_steps": 100,
"train_text_encoder": true,
"text_encoder_lr": 0.000005
}'
doneVisualizing a training run
Here’s an example training job that got interrupted twice and was able to resume and complete training on a different node each time. The smaller marks are heartbeat events emitted by the worker every 30s, color-coded by machine ID. We can see that this run sat in the queue for 5.4 hours before a worker picked it up and ran for 54:00 of billable time, which is calculated as the number of heartbeats * 30s. Plugging that into the Pricing Calculator, we see a cost of $0.324/hour at high priority, so a total cost of $0.2916 to train the model and the text encoder for 1400 steps. This comes out to $**0.000208/**step. At batch pricing, the cost is significantly lower, $0.204/hour or $0.00013/step , The amount of time taken, and therefore the cost varies greatly based on the parameters you use for training. Training the text encoder slows down training. Using prior preservation also slows down training. More steps take longer. It’s interesting to note that although the run was interrupted multiple times, these interruptions cost less than 4 minutes of clock time, and the run still finished in the median amount of time.
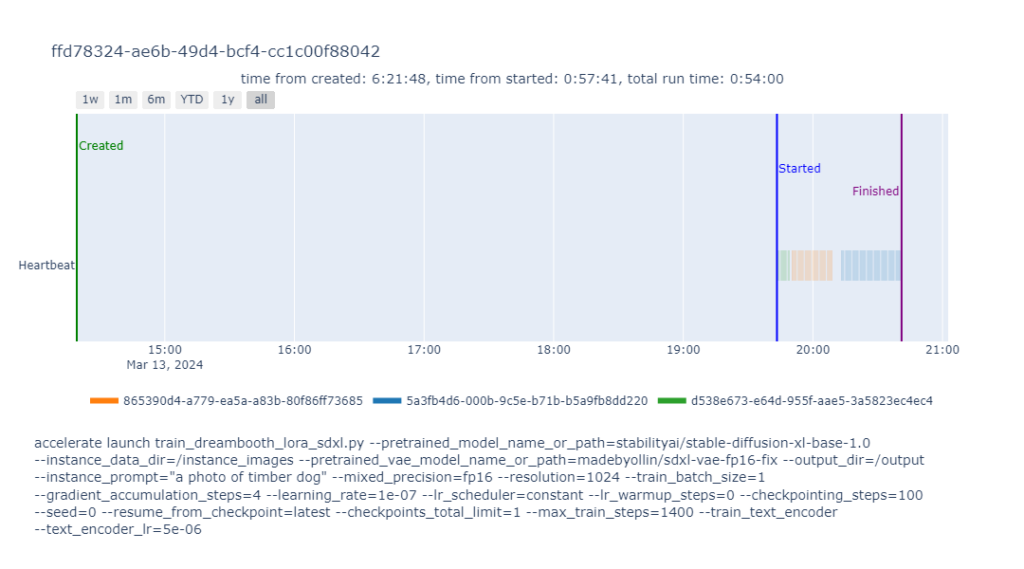
Results from the Stable Diffusion XL fine-tuning
- All 1000 jobs were completed successfully!
- Average Time Taken Per Training Job: 62.01 minutes (2.66s per training step)
- Minimum Time Taken: 41.95 minutes (1.80s per training step)
- Average Cost Per Training Job: $0.2108 at batch priority ($0.00015 per training step)
- Minimum Cost: $0.1426 at batch priority($0.00010 per training step)
- 90.1% of jobs were completed on one node with zero interruptions.
- 9% of jobs were interrupted once, requiring 2 nodes to complete training.
- The remaining 0.9% of jobs required 3 or more nodes to complete training.
Tips and Observations
- Train the text encoder. It makes a huge difference.
- More steps with a lower learning rate typically yielded better results.
- Including the type of animal (e.g. “dog”) in the instance prompt and in validation prompts yielded much better results than just using the name alone. E.g. an instance prompt like “a photo of timber dog” performed much better than just “timber”.
- As with image generation, there is a considerable amount of skill involved in getting consistently good results from training. You’ll need to experiment by trying different prompts and parameters until you get the results you like.
- We checkpointed every 100 steps for this, and that seems to have worked well, with interruptions costing relatively little time.
- I found the Cloudflare developer platform very easy to work with and very reasonably priced. Their
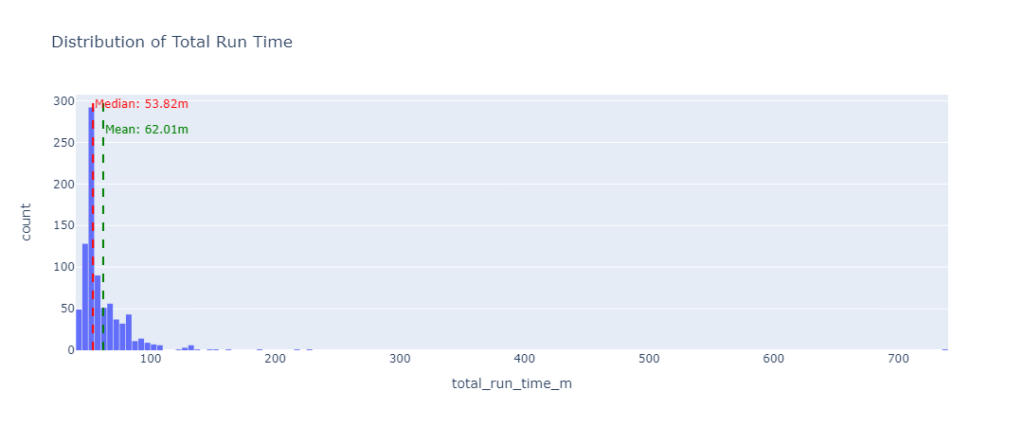
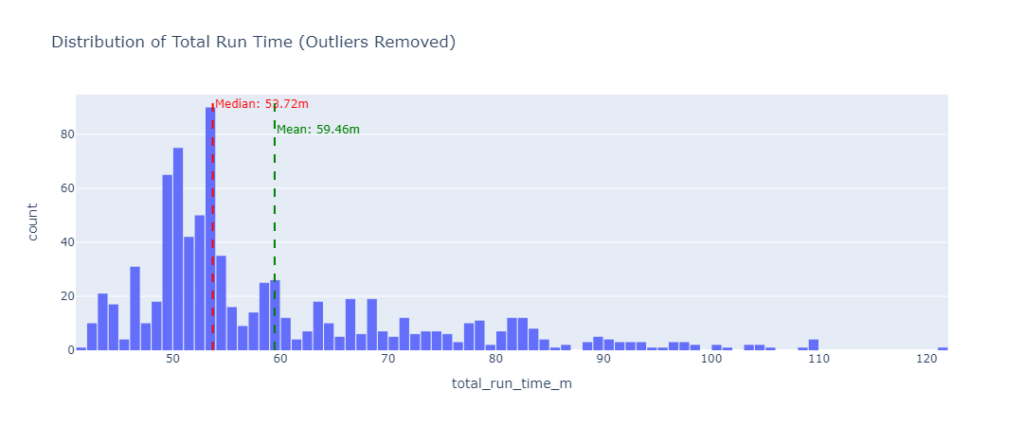
wranglercli lets you do all kinds of things, and the local development experience is very good, letting you use all of the Cloudflare services locally without interfering with your production resources. - There was some variance in how long jobs took to complete, with a minimum time of 41.95 minutes, a maximum time of 737.92 minutes, and a median time of 53.82 minutes. You can see in the charts below that the vast majority of jobs finish within 1 hour, with the 737.92 minute run representing a substantial outlier. You can also see that the mean time is pulled up from the median by the long tail of slower runs.
Future Improvements
- One very time-consuming part of the training process, as implemented in the training script we pulled from diffusers, is that to generate periodic validation images, it must reload all the model components for inference, generate the images, and then reload all the model components again for training. These interruptions can double (or worse) the amount of time needed to train a LoRA, depending on how often you want to generate validation images. Performing validation inference asynchronously would significantly improve training throughput. This would be implemented by bypassing the original script’s validation logic and instead queueing validation inference jobs as checkpoints are created and uploaded. A separate pool of workers would then pull these inference jobs and handle uploading the results to Weights And Balances or whatever tracking platform you decide to use. In this way, the training process would not need to be interrupted for validation.
- While we did manage to automatically purge nodes that proved incapable of completing the training task, we did not filter for unreasonably slow nodes. For instance, while the mean training time for this task was 62 minutes, the absolute worst performance came in 12x worse at 738 minutes. This case was sufficiently rare that removing such outliers from the results makes very little difference in the mean cost of the entire batch (see charts above). Still, in the future, armed with this baseline performance information, we could monitor for machines which are working too slowly (e.g. 2 standard deviations slower), and add them to the banned worker records.
- In the event there is 1 worker node, and 1 available job, it is possible for the worker to be banned for that job, but unable to accumulate enough failures to be automatically reallocated. This will result in the final job not completing until the node is reallocated manually, or naturally. This could be accounted for in the autoscaling code. Our test required 1 manual reallocation due to this scenario.
- This implementation used a pre-written script, unmodified, to actually perform the training. It’s very likely there are details which could be made more efficient by more deeply integrating the training logic into the worker code. For instance, we don’t really need to save checkpoints to the file system at all, but could instead directly upload them as they’re created.
- The solution, as implemented, assumes a single user and notably lacks any sort of permission management. To build this into a commercial service, you’d likely need to integrate ownership concepts and permission management.
- Since training jobs may complete many hours after they are submitted, a notification system would be nice, to alert a user when their model is ready to download. Currently, a user would need to periodically poll the API to check on the status.
Conclusions
Our exploration into fine-tuning Stable Diffusion XL on interruptible GPUs has demonstrated the feasibility and efficiency of our approach, despite the significant challenges posed by training interruptions, capacity limitations, and cost management. Leveraging Cloudflare’s serverless technologies alongside our custom orchestration and autoscaling solutions, we’ve created a resilient and manageable system capable of handling large-scale operations with notable cost efficiency and operational simplicity.
The successes of our deployment, underscored by the seamless completion of 1000/1000 benchmark jobs, highlight the system’s robustness and the potential for further improvements. Future enhancements, such as asynchronous validation and refined node performance assessments, promise to elevate the performance and cost-effectiveness of our service.
Given the extensive amount of experimentation required to get good results, a platform like this can be useful for individuals as well as those seeking to build commercial offerings. Once deployed, a person could submit many different combinations of parameters, prompts, and training data, and run many experiments in parallel.
Resources
- Base Dreambooth Container: GitHub DockerHub
- Dreambooth Job Worker: GitHub DockerHub
- Dreambooth Orchestration API: GitHub
- Dreambooth Autoscaling: GitHub
- SaladCloud Pricing Calculator
- Cloudflare Services
- Dreambooth SDXL LoRA Training Example
- Weights And Biases
- itty-router-openapi – A teeny tiny API router that serves swagger docs and an openapi definition
- Kelpie – An open source implementation of the pattern described here.


