
Reliability in Times of AI GPU Shortage
In the world of cloud computing, leading providers have traditionally utilized expansive, state-of-the-art data centers to ensure top-tier reliability. These data centers, boasting redundant power supplies, cooling systems, and vast network infrastructures, often promise uptime figures ranging from 99.9% to 99.9999% – terms you might have heard as “Three Nines” to “Six Nines.”
For those who have engaged with prominent cloud providers, these figures are seen as a gold standard of reliability. However, the cloud computing horizon is expanding. Harnessing the untapped potential of idle gaming PCs is not only a revolutionary departure from conventional models but also a timely response to the massive compute demands of burgeoning AI businesses.
The ‘AI GPU shortage‘ is everywhere today as GPU-hungry businesses are fighting for affordable, scalable computational power. Leveraging gaming PCs, which are often equipped with high-performance GPUs, provides an innovative solution to meet these growing demands.
While this fresh approach offers unparalleled GPU inference rates and wider accessibility, it also presents a unique set of reliability factors to consider. The decentralized nature of a system built on individual gaming PCs does introduce variability. A single gaming PC might typically offer reliability figures between 90-95% (1 to 1.5 nines). At first glance, this might seem significantly different from the high “nines” many are familiar with. However, it’s crucial to recognize that we’re comparing two different models. While an individual gaming PC might occasionally face challenges, from software issues to local power outages, the collective strength of the distributed system ensures redundancy and robustness on a larger scale.
When exploring our cloud solutions, it’s essential to view reliability from a broader perspective. Instead of concentrating solely on the performance of individual nodes, we highlight the overall resilience of our distributed system. This approach offers a deeper insight into our next-generation cloud infrastructure, blending cost-efficiency with reliability in a transformative way, perfectly suited for the computational needs of modern AI-driven businesses and to solve the ongoing AI GPU shortage.
Exploring the New Cloud Landscape
Embracing Distributed Systems
Unlike traditional centralized systems, distributed clouds, particularly those harnessing the power of gaming PCs, operate on a unique paradigm. Each node in this setup is a personal computer, potentially scattered across the globe rather than being clustered in a singular data center.
Navigating Reliability Differences
Nodes based on gaming PCs might individually present a reliability range of 90-95%. Various elements influence this:
- PC Performance: Given their primary function as gaming machines, the configurations and capabilities of these PCs can differ significantly.
- Connectivity: The internet connections backing these PCs might be residential, which can be less consistent than commercial-grade connections.
- User Behavior: Availability can fluctuate if the PC owner chooses to use their machine or if unexpected shutdowns occur.
Unpacking the Benefits of Distributed Systems
Global Redundancy Amidst Climate Change
The diverse geographical distribution of nodes (geo-redundancy) offers an inherent safeguard against the increasing unpredictability of climate change. As extreme weather events, natural disasters, and environmental challenges become more frequent, centralized data centers in vulnerable regions are at heightened risk of disruptions. However, with nodes spread across various parts of the world, the distributed cloud system ensures that if one region faces climate-induced challenges or outages, the remaining global network can compensate, maintaining continuous availability. This decentralized approach not only ensures business continuity in the face of environmental uncertainties but also underscores the importance of forward-thinking infrastructure planning in our changing world.
Seamless Scalability
Distributed systems are designed for effortless horizontal scaling. Integrating more nodes into a group is a straightforward process.
Fortifying Against Localized Disruptions
Understanding the resilience against localized disruptions is pivotal when appreciating the strengths of distributed systems. This is especially evident when juxtaposed against potential vulnerabilities of a centralized model, like relying solely on a specific AWS region such as US-East-1.
- Eliminating Single Points of Failure:
- AWS’s US-East-1: A popular hub, this region supports a significant portion of online infrastructure. However, concentrating all resources here can be risky. Past outages in this region have led to widespread service disruptions despite AWS’s internal backup systems.
- Distributed Gaming PC Networks: The decentralized structure ensures there’s no single point of vulnerability. Even if a considerable number of PCs in a region go offline, perhaps due to a power outage, the system’s overall functionality remains intact.
- Mitigating Geographic Risks:
- AWS’s US-East-1: Located in North Virginia, this region can be vulnerable to localized natural events like hurricanes. Such incidents, albeit infrequent, can disrupt or degrade data center operations.
- Distributed Gaming PC Networks: With nodes spread worldwide, localized natural events like hurricanes or earthquakes affect only a minor portion of the system. The network dynamically reroutes and rebalances loads as required.
- Diversifying Infrastructure Dependencies:
- AWS’s US-East-1: Resources here are dependent on AWS’s infrastructure in North Virginia, encompassing power, connectivity, and AWS’s proprietary software. A glitch in any of these areas impacts all services in the region.
- Distributed Gaming PC Networks: These networks thrive on diverse infrastructure foundations, given their reliance on individual PCs. This diversity minimizes the risk of widespread outages due to a singular component’s failure.
- Preventing Traffic Congestion:
- AWS’s US-East-1: Sudden traffic surges can lead to bottlenecks, especially with numerous services vying for resources in this region.
- Distributed Gaming PC Networks: Traffic is dispersed across global nodes, minimizing the likelihood of any single node becoming overwhelmed.
Catering to AI’s Growing Demands
Harnessing idle gaming PCs is not just innovative but also a strategic response to the escalating computational needs of emerging AI enterprises. As AI technologies advance, the quest for affordable, scalable computational power intensifies. Gaming PCs, often equipped with high-end GPUs, present an ingenious solution to this challenge.

Achieving Lower Latency
The vast geographic distribution of nodes means data can be processed or stored closer to end-users, potentially offering reduced latency for specific applications.
Cost-Effective Solutions
Tapping into the dormant resources of idle gaming PCs can lead to substantial cost savings compared to the expenses of maintaining dedicated data centers.
The Collective Reliability Factor
While individual nodes might have a reliability rate of 90-95%, the combined reliability of the entire system can be significantly higher, thanks to redundancy and the sheer number of nodes.
Consider this analogy:
Flipping a coin has a 50% chance of landing tails. However, flipping two coins simultaneously reduces the probability of both landing tails by 25%. For three coins, it’s 12.5%, and so on.
Applying this to our nodes, if each node has a 10% chance of being offline, the probability of two nodes being offline simultaneously is just 1%. As the number of nodes increases, the likelihood of all of them being offline simultaneously diminishes exponentially.
Thus, as the size of a network grows, the chances of the entire system experiencing downtime decrease dramatically. Even if individual nodes occasionally falter, the distributed nature of the system ensures its overall availability remains impressively high.
Here is a real example: 24 hours sampled from a production AI image generation workload with 100 requested nodes. As we would expect, it’s fairly uncommon for all 100 to be running at the same time, but 100% of the time, we have at least 82 live nodes. For this customer, 82 simultaneous nodes offered plenty of throughput to keep up with their own internal SLOs and provided a 0-downtime experience.
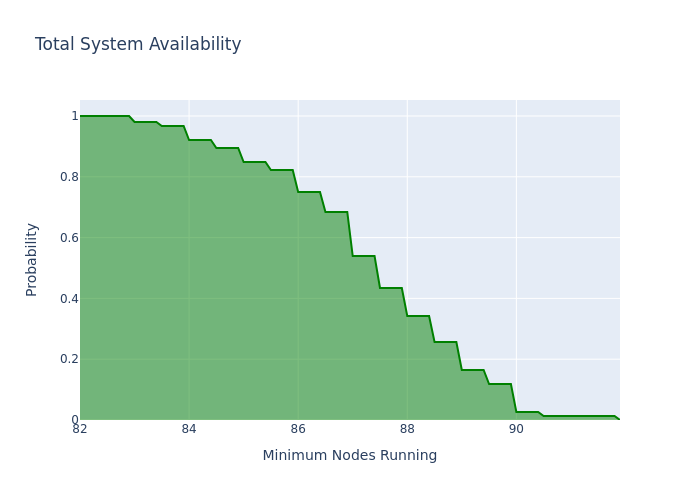
Gaming PCs as a Robust, High-Availability Solution for AI GPU Shortage
While gaming PC nodes might seem to offer modest reliability compared to enterprise servers, when viewed as part of a distributed system, they present a robust, high-availability solution. This system, with its inherent benefits of redundancy, scalability, and resilience, can be expertly managed to provide a formidable alternative to traditional centralized systems. By leveraging the untapped potential of gaming PCs, we not only address the growing computational demands of industries like AI but also pave the way for a more resilient, cost-effective, and globally distributed cloud infrastructure. This paradigm shift not only revolutionizes how we perceive cloud computing but also underscores the importance of adaptability and innovation in the ever-evolving tech landscape.
Strategies for Enhanced Reliability
Statelessness
Statelessness refers to the condition where operations within a system do not depend on any stored state or context from prior operations. Each transaction is treated as an independent event unaffected by previous transactions. This principle has significant advantages in distributed systems, particularly in enhancing reliability:
- Scalability: Stateless systems can easily accommodate a sudden influx of requests because there’s no need to manage or maintain session information. New nodes can be added seamlessly without needing to understand previous interactions.
- Resilience: If a node fails in a stateless system, another node can immediately handle the request without needing any prior knowledge. This ensures continuity in service delivery even in the face of failures.
- Load Balancing: Stateless architectures simplify load balancing. Since any node can handle any request, incoming tasks can be evenly distributed across the system without concern for maintaining session states.
- Simplified Management and Deployment: Without state information to manage, deploying updates, scaling, or making changes to the infrastructure becomes simpler and less error-prone.
- Enhanced Performance: By eliminating the need to store, retrieve, and manage state information, stateless systems can often deliver faster response times.
Queues
Queue-oriented architectures utilize message queues to manage and process requests. These queues act as temporary storage systems for messages or tasks that are waiting to be processed. In the context of distributed system reliability, queue-oriented architectures offer several compelling advantages:
- Decoupling: Queues decouple producers (entities that send messages) from consumers (entities that process messages). This means that even if a consumer node fails, the messages it was meant to process aren’t lost; they remain in the queue to be picked up by another consumer.
- Load Leveling: If the system experiences sudden spikes in requests, queues can help level the load by storing excess messages. Consumer nodes can then process these messages at their own pace without being overwhelmed.
- Redundancy: Messages in the queue can be processed by any available consumer node. If a node fails in the middle of processing, the message can be returned to the queue or picked up by another node, ensuring that no tasks are lost due to node failures.
- Order Preservation: Many queue systems ensure that messages are processed in the order they arrive, maintaining the integrity and logical flow of operations.
- Visibility and Monitoring: Queues allow for better visibility into the system’s operations. Administrators can monitor the length of queues to gauge system load, identify bottlenecks, and predict potential system failures.
- Failover Mechanism: Some advanced queue-oriented architectures support a failover mechanism where if one queue becomes unavailable, messages are automatically routed to a backup queue, ensuring no loss of data or service disruption.
Idempotency
Idempotency is a fundamental concept in both computer science and mathematics. In the context of distributed systems, an operation is said to be idempotent if performing it multiple times yields the same result as performing it once. In other words, duplicate executions won’t have any additional side effects. Idempotency is a cornerstone principle in ensuring reliability, especially in systems where operations might be retried due to failures or uncertainties. Here’s why it’s crucial:
- Fault Tolerance: In distributed systems, requests can fail for a myriad of reasons, including network hiccups, system crashes, or timeouts. If operations are idempotent, failed requests can be safely retried without the fear of unintended consequences or inconsistencies.
- Consistency: Distributed systems often involve multiple nodes that need to stay synchronized. Idempotency ensures that even if multiple nodes perform the same operation due to a miscommunication, the system’s overall state remains consistent.
- Simplified Error Handling: When operations are idempotent, error recovery becomes straightforward. Instead of complex mechanisms to check if an operation should be retried, systems can adopt a simple policy: always retry, knowing there won’t be adverse side effects.
- Improved User Experience: For end-users, idempotency can mean smoother interactions. For instance, if a user submits a form and the response is delayed, they can safely resubmit without fear of duplicate actions like double charges or multiple orders.
- Streamlined System Interactions: In systems where multiple services interact, idempotency ensures that services can communicate repetitively (if needed) without creating data discrepancies.
- Optimized Resource Utilization: Without the need for intricate mechanisms to track and manage each request’s state, resources can be more efficiently utilized, leading to a more performant system.
Implementing Idempotency:
- Unique Identifiers: Assign unique IDs to each request. If a system sees a request with an ID that has already been processed, it can safely ignore or return the already computed response without reprocessing.
- State Markers: Use state markers to indicate the progress or result of operations. Before performing an operation, check the state marker to decide if execution is necessary.
- Locks and Conditional Writes: Implement locks or conditional writes to prevent multiple nodes from simultaneously performing non-idempotent operations.
- Generative AI Specific: Set the random seed at the time the request is generated. This leads to deterministic generation, meaning that if the request gets processed twice, the outcome will be exactly the same.
Aspiring to Elevate the Distributed Cloud System
As we embark on our journey into distributed cloud computing at SaladCloud, we’re setting our sights on establishing a transparent and evolving relationship with our users and stakeholders. We recognize the importance of understanding the nuances of a distributed system, and we’re striving to educate our users about its nature and the trade-offs that come with it. Our goal is to offer real-time metrics on network-wide uptime, node reliability, and performance, ensuring that our users will be well-equipped with the information they need.
Service Level Agreements (SLAs) are on our roadmap, and we’re committed to crafting SLAs that genuinely mirror the anticipated reliability of our network. While we’re cautious about setting the right expectations, we’re also exploring the possibility of introducing premium tiers with enhanced reliability assurances for those who seek that added layer of trust.
At the heart of our aspirations is the community. We envision a robust community where users are incentivized to maintain high reliability. Our aim is to reward those who stand out in terms of uptime and to cultivate platforms for knowledge sharing. We believe that by fostering a space where users can exchange best practices, tips, and tricks, we can harness the collective wisdom of the community to bolster the system’s resilience.
In our pursuit of innovation, we’re looking into leveraging machine learning for predictive maintenance. By training models on historical data, we hope to foresee potential node challenges, enabling us to make proactive decisions and reroute tasks as needed. This forward-thinking approach, coupled with our plans to establish continuous feedback loops, is geared towards ensuring that we’re always on the path of learning and refining our strategies.
In essence, our vision for the distributed cloud system is not merely about tapping into idle gaming PCs. It’s about laying the groundwork for a dynamic, community-centric, and ever-evolving ecosystem. An ecosystem that we hope will captivate potential users and resonate with those eager to be part of a revolutionary shift in cloud computing.
Distributed Clouds: A Win for Reliability
In the evolving landscape of cloud computing, the innovative approach of leveraging idle gaming PCs has emerged as a promising paradigm, bridging the gap between cost-efficiency and high-performance GPU inference capabilities. While traditional data centers have set industry standards with their “Three to Six Nines” of reliability, these figures don’t directly translate to the distributed gaming PC model. With individual nodes presenting reliability rates between 90-95%, it may initially seem like a step back. However, the key lies in understanding the broader resilience offered by the distributed system as a whole. By harnessing principles like statelessness, idempotency, and queue-oriented architectures, we can achieve a harmonious blend of reliability and affordability.


